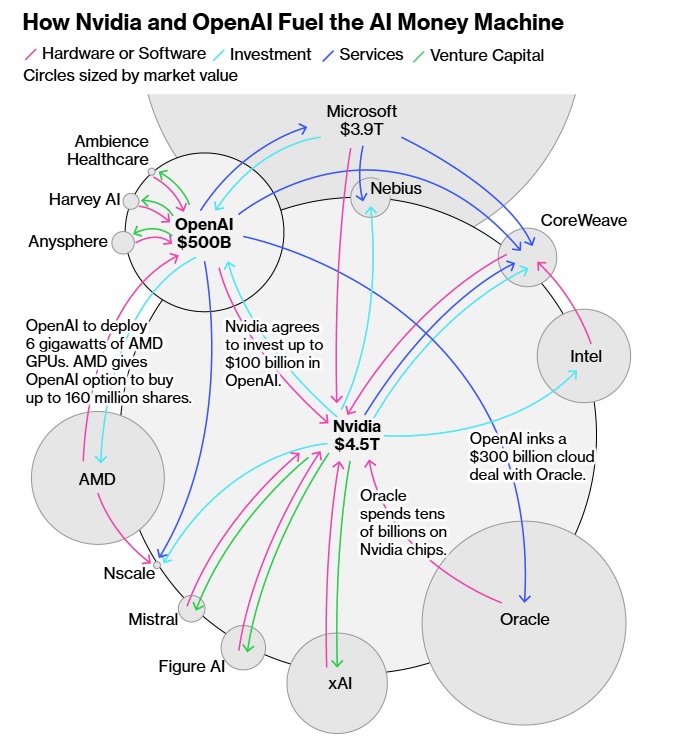
The Trump administration is attempting an impossible contradiction: selling advanced NVIDIA AI chips to China while the Department of Justice prosecutes criminal cases for smuggling the exact same chips into China.
“Operation Gatekeeper has exposed a sophisticated smuggling network that threatens our Nation’s security by funneling cutting-edge AI technology to those who would use it against American interests,” said Ganjei. “These chips are the building blocks of AI superiority and are integral to modern military applications. The country that controls these chips will control AI technology; the country that controls AI technology will control the future. The Southern District of Texas will aggressively prosecute anyone who attempts to compromise America’s technological edge.”
That divergence from the prosecutors is not industrial policy. That is incoherence. But mostly it’s just bad advice, likely coming from White House AI Czar David Sacks, Mr. Trump’s South African AI policy advisor who may have a hard time getting a security clearance in the first place..
On one hand, DOJ is rightly bringing cases over the illegal diversion of restricted AI chips—recognizing that these processors are strategic technologies with direct national-security implications. On the other hand, the White House is signaling that access to those same chips is negotiable, subject to licensing workarounds, regulatory carve-outs, or political discretion.
You cannot treat a technology as contraband in federal court and as a commercial export in the West Wing.
Pick one.
AI Chips Are Not Consumer Electronics
The United States does not sell China F-35 fighter jets. We do not sell Patriot missile systems. We do not sell advanced avionics platforms and then act surprised when they show up embedded in military infrastructure. High-end AI accelerators are in the same category.
NVIDIA’s most advanced chips are not merely commercial products. They are general-purpose intelligence infrastructure or what China calls military-civil fusion. They train surveillance systems, military logistics platforms, cyber-offensive tools, and models capable of operating autonomous weapons and battlefield decision-making pipelines with no human in the loop.
If DOJ treats the smuggling of these chips into China as a serious federal crime—and it should—there is no coherent justification for authorizing their sale through executive discretion. Except, of course, money, or in Mr. Sacks case, more money.

Fully Autonomous Weapons—and Selling the Rope
China does not need U.S. chips to build consumer AI. It wants them for military acceleration.Advanced NVIDIA AI chips are not just about chatbots or recommendation engines. They are the backbone of fully autonomous weapons systems—autonomous targeting, swarm coordination, battlefield logistics, and decision-support models that compress the kill chain beyond meaningful human control.
There is an old warning attributed to Vladimir Lenin—that capitalists would sell the rope by which they would later be hanged. Apocryphal or not, it captures this moment with uncomfortable precision.
If NVIDIA chips are powerful enough to underpin autonomous weapons systems for allied militaries, they are powerful enough to underpin autonomous weapons systems for adversaries like China. Trump’s own National Security Strategy statement clearly says previous U.S. elites made “mistaken” assumptions about China such as the famous one that letting China into the WTO would integrate Beijing into the famous rules-based international order. Trump tells us that instead China “got rich and powerful” and used this against us, and goes on to describe the CCP’s well known predatory subsidies, unfair trade, IP theft, industrial espionage, supply-chain leverage, and fentanyl precursor exports as threats the U.S. must “end.” By selling them the most advanced AI chips?
Western governments and investors simultaneously back domestic autonomous-weapons firms—such as Europe-based Helsing, supported by Spotify CEO Daniel Ek—explicitly building AI-enabled munitions for allied defense. That makes exporting equivalent enabling infrastructure to a strategic competitor indefensible.
The AI Moratorium Makes This Worse, Not Better
This contradiction unfolds alongside a proposed federal AI moratorium executive order originating with Mr. Sacks and Adam Thierer of Google’s R Street Institute that would preempt state-level AI protections.
States are told AI is too consequential for local regulation, yet the federal government is prepared to license exports of AI’s core infrastructure abroad.
If AI is too dangerous for states to regulate, it is too dangerous to export. Preemption at home combined with permissiveness abroad is not leadership. It is capture.
This Is What Policy Capture Looks Like
The common thread is not national security. It is Silicon Valley access. David Sacks and others in the AI–VC orbit argue that AI regulation threatens U.S. competitiveness while remaining silent on where the chips go and how they are used.
When DOJ prosecutes smugglers while the White House authorizes exports, the public is entitled to ask whose interests are actually being served. Advisory roles that blur public power and private investment cannot coexist with credible national-security policymaking particularly when the advisor may not even be able to get a US national security clearance unless the President blesses it.
A Line Has to Be Drawn
If a technology is so sensitive that its unauthorized transfer justifies prosecution, its authorized transfer should be prohibited absent extraordinary national interest. AI accelerators meet that test.
Until the administration can articulate a coherent justification for exporting these capabilities to China, the answer should be no. Not licensed. Not delayed. Not cosmetically restricted.
And if that position conflicts with Silicon Valley advisers who view this as a growth opportunity, they should return to where they belong. The fact that the US is getting 25% of the deal (which i bet never finds its way into America’s general account), means nothing except confirming Lenin’s joke about selling the rope to hang ourselves, you know, kind of like TikTok.
David Sacks should go back to Silicon Valley.
This is not venture capital. This is our national security and he’s selling it like rope.