Deduplication—the process of removing identical or near-identical content from AI training data—is a critical yet often overlooked indicator that AI platforms actively monitor and curate their training sets. This is the kind of process that one would expect given the kind of “scrape, ready, aim” business practices that seems precisely the approach of AI platforms that have ready access to large amounts of fairly high quality data from users of other products placed into commerce by business affiliates or confederates of the AI platforms.
For example, Google Gemini could have access to gmail, YouTube, at least “publicly available” Google Docs, Google Translate, or Google for Education, and then of course one of the great scams of all time, Google Books. Microsoft uses Bing searches, MSN browsing, the consumer Copilot experience, and ad interactions. Amazon uses Alexa prompts, Facebook uses “public” posts and so on.
This kind of hoovering up of indiscriminate amounts of “data” in the form of your baby pictures posted on Facebook and your user generated content on YouTube is bound to produce duplicates. After all, how may users have posted their favorite Billie Eilish or Taylor Swift music video. AI doesn’t need 10000 versions of “Shake it Off” they probably just need the official video. Enter deduplication–which by definition means the platform knows what it has scraped and also knows what it wants to get rid of.
“Get rid of” is a relative concept. In many systems—particularly in storage environments like backup servers or object stores—deduplication means keeping only one physical copy of a file. Any other instances of that data don’t get stored again; instead, they’re represented by pointers to the original copy. This approach, known as inline deduplication, happens in real time and minimizes storage waste without actually deleting anything of functional value. It requires knowing what you have, knowing you have more than one version of the same thing, and being able to tell the system where to look to find the “original” copy without disturbing the process and burning compute inefficiently.
In other cases, such as post-process deduplication, the system stores data initially, then later scans for and eliminates redundancies. Again, the AI platform knows there are two or more versions of the same thing, say the book Being and Nothingness, knows where to find the copies and has been trained to keep only one version. Even here, the duplicates may not be permanently erased—they might be archived, versioned, or logged for auditing, compliance, or reconstruction purposes.
In AI training contexts, deduplication usually means removing redundant examples from the training set to avoid copyright risk. The duplicate content may be discarded from the training pipeline but often isn’t destroyed. Instead, AI companies may retain it in a separate filtered corpus or keep hashed fingerprints to ensure future models don’t retrain on the same material unknowingly.
So they know what they have, and likely know where it came from. They just don’t want to tell any plaintiffs.
Ultimately, deduplication is less about destruction and more about optimization. It’s a way to reduce noise, save resources, and improve performance—while still allowing systems to track, reference, or even rehydrate the original data if needed.
Its existence directly undermines claims that companies are unaware of which copyrighted works were ingested. Indeed, it only makes sense that one of the hidden consequences of the indiscriminate scraping that underpins large-scale AI training is the proliferation of duplicated data. Web crawlers ingest everything they can access—news articles republished across syndicates, forum posts echoed in aggregation sites, Wikipedia mirrors, boilerplate license terms, spammy SEO farms repeating the same language over and over. Without any filtering, this avalanche of redundant content floods the training pipeline.
This is where deduplication becomes not just useful, but essential. It’s the cleanup crew after a massive data land grab. The more messy and indiscriminate the scraping, the more aggressively the model must filter for quality, relevance, and uniqueness to avoid training inefficiencies or—worse—model behaviors that are skewed by repetition. If a model sees the same phrase or opinion thousands of times, it might assume it’s authoritative or universally accepted, even if it’s just a meme bouncing around low-quality content farms.
Deduplication is sort of the Winston Wolf of AI. And if the cleaner shows up, somebody had to order the cleanup. It is a direct response to the excesses of indiscriminate scraping. It’s both a technical fix and a quiet admission that the underlying data collection strategy is, by design, uncontrolled. But while the scraping may be uncontrolled to get copies of as much of your data has they can lay hands on, even by cleverly changing their terms of use boilerplate so they can do all this under the effluvia of legality, they send in the cleaner to take care of the crime scene.
So to summarize: To deduplicate, platforms must identify content-level matches (e.g., multiple copies of Being and Nothingness by Jean-Paul Sartre). This process requires tools that compare, fingerprint, or embed full documents—meaning the content is readable and classifiable–and, oh, yes, discoverable.
Platforms may choose the ‘cleanest’ copy to keep, showing knowledge and active decision-making about which version of a copyrighted work is retained. And–big finish–removing duplicates only makes sense if operators know which datasets they scraped and what those datasets contain.
Drilling down on a platform’s deduplication tools and practices may prove up knowledge and intent to a precise degree—contradicting arguments of plausible deniability in litigation. Johnny ate the cookies isn’t going to fly. There’s a market clearing level of record keeping necessary for deduping to work at all, so it’s likely that there are internal deduplication logs or tooling pipelines that are discoverable.
When AI platforms object to discovery about deduplication, plaintiffs can often overcome those objections by narrowing their focus. Rather than requesting broad details about how a model deduplicates its entire training set, plaintiffs should ask a simple, specific question: Were any of these known works—identified by title or author—deduplicated or excluded from training?
This approach avoids objections about overbreadth or burden. It reframes discovery as a factual inquiry, not a technical deep dive. If the platform claims the data was not retained, plaintiffs can ask for existing artifacts—like hash filters, logs, or manifests—or seek a sworn statement explaining the loss and when it occurred. That, in turn, opens the door to potential spoliation arguments.
If trade secrets are cited, plaintiffs can propose a protective order, limiting access to outside counsel or experts like we’ve done 100,000 times before in other cases. And if the defendant claims “duplicate” is too vague, plaintiffs can define it functionally—as content that’s identical or substantially similar, by hash, tokens, or vectors.
Most importantly, deduplication is relevant. If a platform identified a plaintiff’s work and trained on it anyway, that speaks to volitional use, copying, and lack of care—key issues in copyright and fair use analysis. And if they lied about it, particularly to the court—Helloooooo Harper & Row. Discovery requests that are focused, tailored, and anchored in specific works stand a far better chance of surviving objections and yielding meaningful evidence which hopefully will be useful and lead to other positive results.
For too long, dominant tech platforms have hidden behind Section 230 of the Communications Decency Act, claiming immunity for any harm caused by third-party content they host or promote. But as platforms like TikTok, YouTube, and Google have long ago moved beyond passive hosting into highly personalized, behavior-shaping recommendation systems, the legal landscape is shifting in the personal injury context. A new theory of liability is emerging—one grounded not in speech, but in conduct. And it begins with a simple premise: the duty comes from the data.
Modern platforms know more about their users than most doctors, priests, or therapists. Through relentless behavioral surveillance, they collect real-time information about users’ moods, vulnerabilities, preferences, financial stress, and even mental health crises. This data is not inert or passive. It is used to drive engagement by pushing users toward content that exploits or heightens their current state.
If the user is a minor, a person in distress, or someone financially or emotionally unstable, the risk of harm is not abstract. It is foreseeable. When a platform knowingly recommends payday loan ads to someone drowning in debt, promotes eating disorder content to a teenager, or pushes a dangerous viral “challenge” to a 10-year-old child, it becomes an actor, not a conduit. It enters the “range of apprehension,” to borrow from Judge Cardozo’s reasoning in Palsgraf v. Long Island Railroad (one of my favorite law school cases). In tort law, foreseeability or knowledge creates duty. And here, the knowledge is detailed, intimate, and monetized. In fact it is so detailed we had to coin a new name for it: Surveillance capitalism.
Algorithmic Recommendations as Calls to Action
Defenders of platforms often argue that recommendations are just ranked lists—neutral suggestions, not expressive or actionable speech. But I think in the context of harm accruing to users for whatever reason, speech misses the mark. The speech argument collapses when the recommendation is designed to prompt behavior. Let’s be clear, advertisers don’t come to Google because speech, they come to Google because Google can deliver an audience. As Mr. Wanamaker said, “Half the money I spend on advertising is wasted; the trouble is I don’t know which half.” If he’d had Google, none of his money would have been wasted–that’s why Google is a trillion dollar market cap company.
When TikTok serves the same deadly challenge over and over to a child, or Google delivers a “pharmacy” ad to someone seeking pain relief that turns out to be a fentanyl-laced fake pill, the recommendation becomes a call to action. That transforms the platform’s role from curator to instigator. Arguably, that’s why Google paid a $500,000,000 fine and entered a non prosecution agreement to keep their executives out of jail. Again, nothing to do with speech.
Calls to action have long been treated differently in tort and First Amendment law. Calls to action aren’t passive; they are performative and directive. Especially when based on intimate surveillance data, these prompts and nudges are no longer mere expressions—they are behavioral engineering. When they cause harm, they should be judged accordingly. And to paraphrase the gambling bromide, the get paid their money and they takes their chances.
Eggshell Skull Meets Platform Targeting
In tort law, the eggshell skull rule (Smith v. Leech Brain & Co. Ltd. my second favorite law school tort case) holds that a defendant must take their victim as they find them. If a seemingly small nudge causes outsized harm because the victim is unusually vulnerable, the defendant is still liable. Platforms today know exactly who is vulnerable—because they built the profile. There’s nothing random about it. They can’t claim surprise when their behavioral nudges hit someone harder than expected.
When a child dies from a challenge they were algorithmically fed, or a financially desperate person is drawn into predatory lending through targeted promotion, or a mentally fragile person is pushed toward self-harm content, the platform can’t pretend it’s just a pipeline. It is a participant in the causal chain. And under the eggshell skull doctrine, it owns the consequences.
Beyond 230: Duty, Not Censorship
This theory of liability does not require rewriting Section 230 or reclassifying platforms as publishers although I’m not opposed to that review. It’s a legal construct that may have been relevant in 1996 but is no longer fit for purpose. Duty as data bypasses the speech debate entirely. What it says is simple: once you use personal data to push a behavioral outcome, you have a duty to consider the harm that may result and the law will hold you accountable for your action. That duty flows from knowledge, very precise knowledge that is acquired with great effort and cost for a singular purpose–to get rich. The platform designed the targeting, delivered the prompt, and did so based on a data profile it built and exploited. It has left the realm of neutral hosting and entered the realm of actionable conduct.
Courts are beginning to catch up. The Third Circuit’s 2024 decision in Anderson v. TikTok reversed the district court and refused to grant 230 immunity where the platform’s recommendation engine was seen as its own speech. But I think the tort logic may be even more powerful than a 230 analysis based on speech: where platforms collect and act on intimate user data to influence behavior, they incur a duty of care. And when that duty is breached, they should be held liable.
The duty comes from the data. And in a world where your data is their new oil, that duty is long overdue.
For a moment, it looked like the tech world’s powerbrokers had pulled it off. Buried deep in a Republican infrastructure and tax package was a sleeper provision — the so-called AI moratorium — that would have blocked states from passing their own AI laws for up to a decade. It was an audacious move: centralize control over one of the most consequential technologies in history, bypass 50 state legislatures, and hand the reins to a small circle of federal agencies and especially to tech industry insiders.
But then it collapsed.
The Senate voted 99–1 to strike the moratorium. Governors rebelled. Attorneys general sounded the alarm. Artists, parents, workers, and privacy advocates from across the political spectrum said “no.” Even hardline conservatives like Ted Cruz eventually reversed course when it came down to the final vote. The message to Big Tech or the famous “Little Tech” was clear: the states still matter — and America’s tech elite ignore that at their peril. (“Little Tech” is the latest rhetorical deflection promoted by Big Tech aka propaganda.)
The old Google crowd pushed the moratorium–their fingerprints were obvious. Having gotten fabulously rich off of their two favorites: The DMCA farce and the Section 230 shakedown. But there’s increasing speculation that White House AI Czar and Silicon Valley Viceroy David Sacks, PayPal alum and vocal MAGA-world player, was calling the ball. If true, that makes this defeat even more revealing.
Sacks represents something of a new breed of power-hungry tech-right influencer — part of the emerging “Red Tech” movement that claims to reject woke capitalism and coastal elitism but still wants experts to shape national policy from Silicon Valley, a chapter straight out of Philip Dru: Administrator. Sacks is tied to figures like Peter Thiel, Elon Musk, and a growing network of Trump-aligned venture capitalists. But even that alignment couldn’t save the moratorium.
Why? Because the core problem wasn’t left vs. right. It was top vs. bottom.
In 1964, Ronald Reagan’s classic speech called A Time for Choosing warned about “a little intellectual elite in a far-distant capitol” deciding what’s best for everyone else. That warning still rings true — except now the “capitol” might just be a server farm in Menlo Park or a podcast studio in LA.
The AI moratorium was an attempt to govern by preemption and fiat, not by consent. And the backlash wasn’t partisan. It came from red states and blue ones alike — places where elected leaders still think they have the right to protect their citizens from unregulated surveillance, deepfakes, data scraping, and economic disruption.
So yes, the defeat of the moratorium was a blow to Google’s strategy of soft-power dominance. But it was also a shot across the bow for David Sacks and the would-be masters of tech populism. You can’t have populism without the people.
If Sacks and his cohort want to play a long game in AI policy, they’ll have to do more than drop ideas into the policy laundry of think tank white papers and Beltway briefings. They’ll need to win public trust, respect state sovereignty, and remember that governing by sneaky safe harbors is no substitute for legitimacy.
The moratorium failed because it presumed America could be governed like a tech startup — from the top, at speed, with no dissent. Turns out the country is still under the impression they have something to say about how they are governed, especially by Big Tech.
In an unprecedented move, the Japan Fair Trade Commission on Tuesday issued a cease-and-desist order against Google for violating the country's anti-monopoly law by forcing manufacturers to preinstall the company’s apps on their Android smartphones.https://t.co/ycsxX1s8tR
Damian Collins (former chair of the UK Parliament’s Digital Culture Media and Sport Select Committee) warns of Google’s latest AI shenanigans in a must-read opinion piece in the Daily Mail that highlights Google’s attempt to lobby its way into what is essentially a retroactive safe harbor to protect Google and its confederates in the AI land grab. While Mr. Collins writes about Google’s efforts to rewrite the laws of the UK to free ride in his home country which is egregious bullying, the episode he documents is instructive for all of us. If Google & Co. will do it to the Mother of Parliaments, it’s only a matter of time until Google & Co. do the same everywhere or know the reason why. Their goal is to hoover up all the world’s culture that the AI platforms have not scraped already and–crucially–to get away with it. And as Guy Forsyth says, “…nothing says freedom like getting away with it.”
The timeline of AI’s appropriation of all the world’s culture is a critical understanding to appreciate just how depraved Big Tech’s unbridled greed really is. The important thing to remember is that AI platforms like Google have been scraping the Internet to train their AI for some time now, possibly many years. This apparently includes social media platforms they control. My theory is that Google Books was an early effort at digitization for large language models to support products like corpus machine translation as a predecessor to Gemini (“your twin”) and other Google AI products. We should ask Ray Kurzweil.
There is starting to be increasing evidence that this is exactly what these people are up to.
The New York Times Uncovers the Crimes
According to an extensive long-form report in the New York Times by a team of very highly respected journalists, it turns out that Google has been planning this “Text and Data Mining” land grab for some time. At the very moment YouTube was issuing press releases about their Music AI Incubator and their “partners”–Google was stealing anything that was not nailed down that anyone had hosted on their massive platforms, including Google Docs, Google Maps, and…YouTube. The Times tells us:
Google transcribed YouTube videos to harvest text for its A.I. models, five people with knowledge of the company’s practices said. That potentially violated the copyrights to the videos, which belong to their creators….Google said that its A.I. models “are trained on some YouTube content,” which was allowed under agreements with YouTube creators, and that the company did not use data from office apps outside of an experimental program.
I find it hard to believe that YouTube was both allowed to transcribe and scrape under all its content deals, or that they parsed through all videos to find the unprotected ones subject to their interpretation of the YouTube terms of use. So as we say in Texas, that sounds like bullshit for starters.
How does this relate to the Text and Data Mining exception that Mr. Collins warns of? Note that the NYT tells us “Google transcribed YouTube videos to harvest text.” That’s a clue.
As Mr. Collins tells us:
Google [recently] published a policy paper entitled: Unlocking The UK’s AI Potential.
What’s not to like?, you might ask. Artificial intelligence has the potential to revolutionise our economy and we don’t want to be left behind as the rest of the world embraces its benefits.
But buried in Google’s report is a call for a ‘text and data mining’ (TDM) exception to copyright.
This TDM exception would allow Google to scrape the entire history of human creativity from the internet without permission and without payment.
And, of course, Mr. Collins is exactly correct, that’s exactly what Google have in mind.
The Conspiracy of Dunces and the YouTube Fraud
In fairness, it wasn’t just Google ripping us off, but Google didn’t do anything to stop it as far as I can tell. One thing to remember is that YouTube was, and I think still is, not very crawlable by outsiders. It is almost certainly the case that Google would know who was crawling youtube.com, such as Bingbot, DuckDuckBot, Yandex Bot, or Yahoo Slurp if for no other reason that those spiders were not googlebot. With that understanding, the Times also tells us:
OpenAI researchers created a speech recognition tool called Whisper. It could transcribe the audio from YouTube videos, yielding new conversational text that would make an A.I. system smarter.
Some OpenAI employees discussed how such a move might go against YouTube’s rules, three people with knowledge of the conversations said. YouTube, which is owned by Google, prohibits use of its videos for applications that are “independent” of the video platform. [Whatever “independent” means.]
Ultimately, an OpenAI team transcribed more than one million hours of YouTube videos, the people said. The team included Greg Brockman, OpenAI’s president, who personally helped collect the videos, two of the people said. The texts were then fed into a system called GPT-4, which was widely considered one of the world’s most powerful A.I. models and was the basis of the latest version of the ChatGPT chatbot….
OpenAI eventually made Whisper, the speech recognition tool, to transcribe YouTube videos and podcasts, six people said. But YouTube prohibits people from not only using its videos for “independent” applications, but also accessing its videos by “any automated means (such as robots, botnets or scrapers).”
OpenAI employees knew they were wading into a legal gray area, the people said, but believed that training A.I. with the videos was fair use.
And strangely enough, many of the AI platforms sued by creators raise “fair use” as a defense (if not all of the cases) which is strangely reminiscent of the kind of crap we have been hearing from these people since 1999.
Now why might Google have permitted OpenAI to crawl YouTube and transcribe videos (and who knows what else)? Probably because Google was doing the same thing. In fact, the Times tells us:
Some Google employees were aware that OpenAI had harvested YouTube videos for data, two people with knowledge of the companies said. But they didn’t stop OpenAI because Google had also used transcripts of YouTube videos to train its A.I. models, the people said. That practice may have violated the copyrights of YouTube creators. So if Google made a fuss about OpenAI, there might be a public outcry against its own methods, the people said.
So Google and its confederate OpenAI may well have conspired to commit massive copyright infringement against the owner of a valid copyright, did so willingly, and for purposes of commercial advantage and private financial gain. (Attempts to infringe are prohibited to the same extent as the completed act). The acts of these confederates vastly exceed the limits for criminal prosecution for both infringement and conspiracy.
But to Mr. Collins’ concern, the big AI platforms transcribed likely billions of hours of YouTube videos to manipulate text and data–you know, TDM.
The New Retroactive Safe Harbor: The Flying Googles Bring their TDM Circus Act to the Big TentWith Retroactive Acrobatics
But also realize the effect of the new TDM exception that Google and their Big Tech confederates are trying to slip past the UK government (and our own for that matter). A lot of the discussion about AI rulemaking acts as if new rules would be for future AI data scraping. Au contraire mes amis–on the contrary, the bad acts have already happened and they happened on an unimaginable scale.
So what Google is actually trying to do is get the UK to pass a retroactive safe harbor that would deprive citizens of valuable property rights–and also pass a prospective safe harbor so they can keep doing the bad acts with impunity.
Fortunately for UK citizens, the UK Parliament has not passed idiotic retroactive safe harbor legislation like the U.S. Congress has. I am, of course, thinking of the vaunted Music Modernization Act (MMA) that drooled its way to a retroactive safe harbor for copyright infringement, a shining example of the triumph of corruption that has yet to be properly challenged in the US on Constitutional grounds.
There’s nothing like the MMA absurdity in the UK, at least not yet. However, that retroactive safe harbor was not lost on Google, who benefited directly from it. They loved it. They hung it over the mantle next to their other Big Game trophy, the DMCA. And now they’d like to do it again for the triptych of legislative taxidermy.
Because make no mistake–a retroactive safe harbor would be exactly the effect of Google’s TDM exception. Not to mention it would also be a form of retroactive eminent domain, or what the UK analogously might call the compulsory purchase of property under the Compulsory Purchase of Property Act. Well…”purchase” might be too strong a word, more like “transfer” because these people don’t intend to pay for a thing.
The effect of passing Google’s TDM exception would be to take property rights and other personal rights from UK citizens without anything like the level of process or compensation required under the Compulsory Purchase of Property–even when the government requires the sale of private property to another private entity (such as a railroad right of way or a utility easement).
The government is on very shaky ground with a TDM exception imposed by the government for the benefit of a private company, indeed foreign private companies who can well afford to pay for it. It would be missing government oversight on a case-by-base basis, no proper valuation, and for entirely commercial purposes with no public benefit. In the US, it would likely violate the Takings Clause of our Constitution, among other things.
It’s Not Just the Artists
Mr. Collins also makes a very important point that might get lost among the stars–it’s not just the stars that AI is ripping off–it is everyone. As the New York Times story points out (and it seems that there’s more whistleblowers on this point every day), the AI platforms are hoovering up EVERYTHING that is on the Internet, especially on their affiliated platforms. That includes baby videos, influencers, everything.
This is why it is cultural appropriation on a grand scale, indeed a scale of depravity that we haven’t seen since the Nurenberg Trials. A TDM exception would harm all Britons in one massive offshoring of British culture.
The Internet is an extraordinary electricity hog. You know this intuitively even if you’ve never studied the question of just how big a hog it really is. AI has already taken that electricity use to exponentially extraordinary new levels. These hogs will ultimately consume the farm if that herd is not thinned out.
This is nothing new. Consider YouTube. First of all, YouTube has long been the second largest search engine in the world. So there’s that. Reportedly, YouTube’s aggregate audience watches over 1 billion viewing hours per day.
To put that in context, the electricity burned by YouTubers works out to approximately 600 terawatt-hours (TWh) per year. (A terawatt hour (TWh) is a unit of energy that represents the amount of work done by one terawatt of power in one hour. The prefix ‘tera’ signifies 10^12. Therefore, one terawatt equals one trillion (1,000,000,000,000 or 10^12) watts.)
According to de Vries, “In 2021, Google’s total electricity consumption was 18.3 TWh, with AI accounting for 10%–15% of this total. The worst-case scenario suggests Google’s AI alone could consume as much electricity as a country such as Ireland (29.3 TWh per year), which is a significant increase compared to its historical AI-related energy consumption.” Remember, that’s just Google.
Bitcoin mining consumes a significant amount of electricity. In May 2023, Bitcoin mining was estimated to consume around 95.58 terawatt-hours of electricity. It reached its highest annual electricity consumption in 2022, peaking at 204.5 terawatt-hours, surpassing the power consumption of Finland.
Back to AI, remember that Big Tech requires big data centers. According to Bloomberg, AI is currently–no pun intended–currently using so much electrical power that coal plants that utilities planned to shut down for climate sustainability are either staying online or being brought back online if they had been shut down. For example, Virginia has been suffering from this surge in usage:
In a 30-square-mile patch of northern Virginia that’s been dubbed “data center alley,” the boom in artificial intelligence is turbocharging electricity use. Struggling to keep up, the power company that serves the area temporarily paused new data center connections at one point in 2022. Virginia’s environmental regulators considered a plan to allow data centers to run diesel generators during power shortages, but backed off after it drew strong community opposition.
It’s also important to realize that building data centers in states that are far flung from the Silicon Valley heartland also increases Big Tech’s political clout. This explains why Oregon Senator Ron Wyden is the confederate of the worst of Big Tech’s excesses like child exploitation and of course, copyright. Copyright never had a worse enemy, all because of the huge presence in Oregon of Big Tech’s data centers–not their headquarters or anything obvious.
Wyden with his hand in his own pocket.
A terawatt here and a terawatt there and pretty soon you’re talking about a lot of electricity. So if you’re interested in climate change, there’s a lot of material here to work with. Maybe we do this before we slaughter the cattle, just sayin’.
Emmanuel Legrand prepared an excellent and important study for the European Grouping of Societies of Authors and Composers (GESAC) that identifies crucial effects of streaming on culture, creatives and especially songwriters. The study highlights the cultural effects of streaming on the European markets, but it would be easy to extend these harms globally as Emmanuel observes.
For example, consider the core pitch of streaming services that started long ago with the commercial Napster 2.0 pitch of “Own Nothing, Have Everything”. This call-to-serfdom slogan may sound good but having infinite shelf space with no cutouts or localized offering creates its own cultural imperative. And that’s even if you accept the premise the algorithmically programed enterprise playlists on streaming services should not be subject to the same cultural protections for performers and songwriters as broadcast radio–its main competitor.
[This] massive availability of content on [streaming] platforms is overshadowed by the fact that these services are under no positive obligations to ensure visibility and discoverability of more diverse repertoires, particularly European works….[plus] the initial individual subscription fee of 9.99 (in Euros, US dollars, or British pound) set in 2006, has never increased, despite the exponential growth in the quality, amount of songs, and user-friendliness of music streaming services.
Artists working new recordings, especially in a language other than English, are forced to fight for “shelf space” and “mindshare”–that is, recognition–against every recording ever released. While this was always true theoretically; you never had that same fight the same way at Tower Records.
This is not theoretically true on streaming platforms–it is actually true because these tens of millions of historical recordings are the competition on streaming services. When you look at the global 100 charts for streaming services, almost all of the titles are in English and are largely Anglo-American releases. Yes, we know–Bad Bunny. But this year’s exception proves the rule.
And then Emmanuel notes that it is the back room algorithms–the terribly modern version of the $50 handshake–that support various payola schemes:
The use of algorithms, as well as bottleneck represented by the most popular playlists, exacerbates this. Furthermore, long-standing flaws in the operations of music streaming platforms, such as “streaming fraud”, “ghost/fake artists”, “payola schemes”, “royalty free content” and other coercive practices [not to mention YouTube withholding access to Content ID] worsen the impact on many professional creators….
This report suggests solutions to bring greater transparency in the use of algorithms and invites stakeholders to undertake a review of the economic models of streaming services and evaluate how they currently affect cultural diversity which should be promoted in its various forms — music genres, languages, origin of performers and songwriters, in particular through policy actions.
MTS readers will recall my extensive dives into the hyperefficient market share distribution of streaming royalties known as the “big pool” compared to my “ethical pool” proposal and the “user centric” alternative. As Emmanuel points out, the big pool royalty model belies a cultural imperative–if you are counting streams on a market share basis that results in the rich getting richer based on “stream share” that same stream share almost guarantees that Anglo American repertoire will dominate in every market the big streamers operate.
Emmanuel uses French-Canadian repertoire as an example (a subject I know a fair amount about since I performed and recorded with many vedettes before Quebecoise was cool).
A lot of research has been made in Canada with regards to discoverability, in particular in the context of French-Canadian music, which is subject to quotas for over the air broadcasters which however do not apply to music streaming services. The research shows that while the lists of new releases from Québec studied are present in a large proportion on streaming platforms, they are “not very visible and very little recommended.”
It further shows that the situation is even worse when it is not about new releases, including hit music, when the presence of titles “drops radically.” It is not very difficult to imagine that if we were to swap Québec in the above sentence with the name of any country from the European Union [or any non-Anglo American country], and even with music from the European Union as a whole, we could find similar results.
In other words, there may be aggregators with repertoire in languages other than English that deliver tracks to streamers in their countries, but–absent localized airplay rules–a Spotify user might never know the tracks were there unless the user already knew about the recording, artist or songwriter. (Speaking of Canada, check the MAPL system.)
This is a prime example of why Professor Feijoo and I proposed streaming remuneration in our WIPO study to allow performers to capture the uncompensated capital markets value to the enterprise driven by these performers. Because of the market share royalty system, revenues and royalties do not compensate all performers, particularly regional or non-featured performers (i.e., session players and singers) who essentially get zero compensation for streaming.
Emmanuel also comments on the imbalance in song royalty payments and invites a re-look at how the streaming system biases against songwriters. I would encourage everyone to stop thinking of a pie to be shared or that Johnny has more apples–when the services refuse to raise prices in order to tell a growth story to Wall Street or The City, measuring royalties by a share of some mythical royalty pie is not ever going to get it done. It will just perpetuate a discriminatory system that fails to value the very people on whose backs it was built be they songwriters or session players.
The Securities and Exchange Commission is formalizing ESG disclosures for public companies like Spotify, stating that “[a]s investor demand for climate and other environmental, social and governance (ESG) information soars, the SEC is responding with an all-agency approach” and has taken many actions to require ESG disclosures. It was only a short step for the government to turn disclosure into violations and then turn violations into enforcement:
The Securities and Exchange Commission today announced the creation of a Climate and ESG Task Force in the Division of Enforcement. The task force will be led by Kelly L. Gibson, the Acting Deputy Director of Enforcement, who will oversee a Division-wide effort, with 22 members drawn from the SEC’s headquarters, regional offices, and Enforcement specialized units.
Consistent with increasing investor focus and reliance on climate and ESG-related disclosure and investment, the Climate and ESG Task Force will develop initiatives to proactively identify ESG-related misconduct. The task force will also coordinate the effective use of Division resources, including through the use of sophisticated data analysis to mine and assess information across registrants, to identify potential violations.
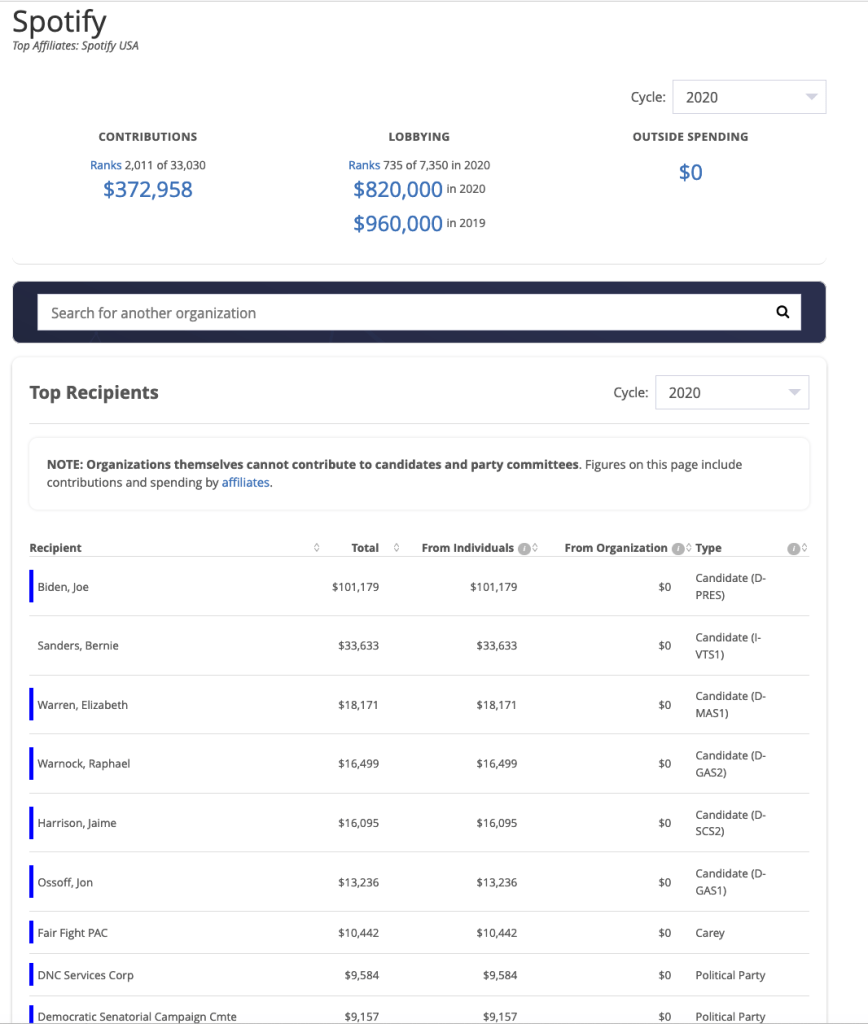
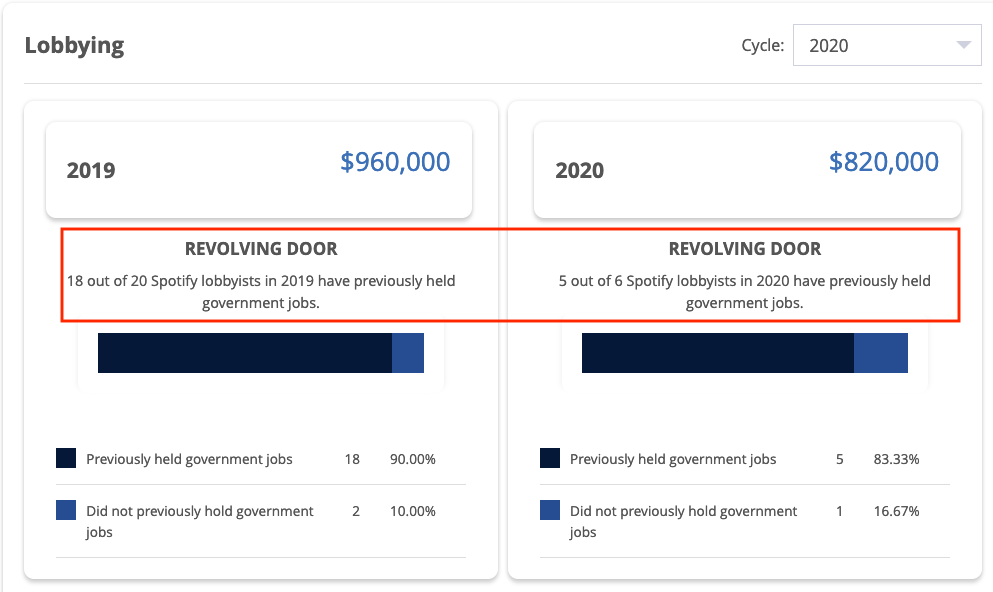
So how does streaming music score on the ESG scale? Let’s take Spotify as an example. (This post brings together several others that readers will recognize.). How bad is Spotify’s ESG competence? Seems pretty bad to me, but probably nothing that Spotify bankers at Goldman Sachs and Spotify’s never ending team of revolving door lobbyists and toadies in the Imperial City can’t get them out of with the right amount of campaign contributions.
Spotify has an ESG problem, and a closer look may offer insights into a wider problem in the tech industry as a whole or at least the streaming business that Spotify dominates. (Another 14% of market share and Spotify will hit that Herfindahl-Hirschman Index sweet spot for those keeping score at home–assuming there’s no change in the number of their competitors.)
If the Spotify decade of destroying artist and songwriter revenues isn’t enough to get your attention, maybe the Neil Young and Joe Rogan imbroglio will. But a minute’s analysis shows you that Spotify was already an ESG fail well before Neil Young’s ultimatum. They give a lot of happy talk about “net zero admissions” and their public messaging is full-on Davos as one would expect from a globalist like Daniel Ek, but streaming is their core business and streaming will only get so green. (It’s unlikely that the FAANG companies (Facebook, Apple, Amazon, Netflix and Google) will allow too much to be made out of the dirty data issue because it blows back directly on them. Neither will Senator Ron Wyden from Oregon the data center concierge–wonder why?)
Streaming is an Environmental Fail
I first began posting about streaming as an environmental fail years ago in the YouTube and Google world. While not as existential as Google’s streaming problems, Spotify is equally sanctimonious about how wonderful Spotify is.
It all comes down to this: The Internet in general and streaming in particular are huge electricity hogs.
Like so many other ways that the BIg Tech PR machine glosses over their dependence on cheap energy right through their supply chain from electric cars to cat videos, YouTube did not want to discuss the company as a climate disaster zone. To hear them tell it, YouTube, and indeed the entire Google megalopolis right down to the Google Street View surveillance team was powered by magic elves dancing on appropriate golden flywheels with suitable work rules. Or other culturally appropriate spin from Google’s ham handed PR teams.
Greenpeace first wrote about “dirty data” in 2011–the year Spotify launched in the US. Too bad Spotify ignored the warnings. Harvard Business Review also tells us that 2011 was a demarcation point for environmental issues at Microsoft following that Greenpeace report:
In 2011, Microsoft’s top environmental and sustainability executive, Rob Bernard, asked the company’s risk-assessment team to evaluate the firm’s exposure. It soon concluded that evolving carbon regulations and fluctuating energy costs and availability were significant sources of risk. In response, Microsoft formed a centralized senior energy team to address this newly elevated strategic issue and develop a comprehensive plan to mitigate risk. The team, comprising 14 experts in electricity markets, renewable energy, battery storage, and local generation (or “distributed energy”), was charged by corporate senior leadership with developing and executing the firm’s energy strategy. “Energy has become a C-suite issue,” Bernard says. “The CFO and president are now actively involved in our energy road map.”
If environment is a C-suite issue at Spotify, there’s no real evidence of it in Spotify’s annual report (but then there isn’t at the Mechanical Licensing Collective, either). “Environment” word search reveals that at Spotify, the environment is “economic”, “credit”, and above all “rapidly changing.” Not “dirty”–or “clean” for that matter.
The fact appears to be that Spotify isn’t doing anything special and nobody seems to want to talk about it. But wait, you say–what about the sainted Music Climate Pact? Guess who hasn’t signed up to the MCP? Any streaming service. There is a “Standard Commitment Letter” that participants are supposed to sign up to but I wasn’t able to read it. Want to guess why?
That’s right. You know who wants to know what you’re up to because they are damn sure not signing up.
Spotify’s ESG Fail: Social
I started to write this post in the pre-Neil Young era and I almost feel like I could stop with the title. But there’s a lot more to it, so let’s look at the many ways Spotify is a fail on the Social part of ESG.
Before Spotify’s Joe Rogan problem, Spotify had both an ethical supply chain problem and a “fair wage” problem on the music side of its business, which for this post we will limit to fair compensation to its ultimate vendors being artists and songwriters. In fact, Spotify is an example to music-tech entrepreneurs of how not to conduct their business.
Treatment of Songwriters
On the songwriter side of the house, let’s not fall into the mudslinging that is going on over the appeal by Spotify (among others) of the Copyright Royalty Board’s ruling in the mechanical royalty rate setting proceeding known as Phonorecords III. Yes, it’s true that streaming screws songwriters even worse that artists, but not only because Spotify exercised its right of appeal of the Phonorecords III case that was pending during the extensive negotiations of Title I of the Music Modernization Act. (Title I is the whole debacle of the Mechanical Licensing Collective and the retroactive copyright infringement safe harbor currently being litigated on Constitutional grounds.)
The main reason that Spotify had the right to appeal available to it after passing the MMA was because the negotiators of Title I didn’t get all of the services to give up their appeal right (called a “waiver”) as a condition of getting the substantial giveaways in the MMA. A waiver would have been entirely appropriate given all the goodies that songwriters gave away in the MMA. When did Noah build the Ark? Before the rain. The negotiators might have gotten that message if they had opened the negotiations to a broader group, but they didn’t so now they’ve got the hot potato no matter how much whinging they do.
Having said that, you will notice that Apple took pity on this egregious oversight and did not appeal the Phonorecords III ruling. You don’t always have to take advantage of your vendor’s negotiating failures, particularly when you are printing money and when being generous would help your vendor keep providing songs. And Mom always told me not to mock the afflicted. Plus it’s good business–take Walmart as an example. Walmart drives a hard bargain, but they leave the vendor enough margin to keep making goods, otherwise the vendor will go under soon or run a business solely to service debt only to go under later. And realize that the decision to be generous is pretty much entirely up to Walmart. Spotify could do the same.
Is being cheap unethical? Is leveraging stupidity unethical? Is trying to recover the costs of the MLC by heavily litigating streaming mechanicals unethical (or unexpected)? Maybe. A great man once said failing to be generous is the most expensive mistake you’ll ever make. So yes, I do think it is unethical although that’s a debatable point. Spotify has not made themselves many friends by taking that course. But what is not debatable is Spotify’s unethical treatment of artists.
Treatment of Artists
The entire streaming royalty model confirms what I call “Ek’s Law” which is related to “Moore’s Law”. Instead of chip speed doubling every 18 months in Moore’s Law, royalties are cut in half every 18 months with Ek’s Law. This reduction over time is an inherent part of the algebra of the streaming business model as I’ve discussed in detail in Arithmetic on the Internet as well as the study I co-authored with Dr. Claudio Feijoo for the World Intellectual Property Organization. These writings have caused a good deal of discussion along with the work of Sharky Laguana about the “Big Pool” or what’s come to be called the “market centric” royalty model.
Dissatisfaction with the market centric model has led to a discussion of the “user-centric” model as an alternative so that fans don’t pay for music they don’t listen to. But it’s also possible that there is no solution to the streaming model because everybody whose getting rich (essentially all Spotify employees and owners of big catalogs) has no intention of changing anything voluntarily.
It would be easy to say “fair is where we end up” and write off Ek’s Law as just a function of the free market. But the market centric model was designed to reward a small number of artists and big catalog owners without letting consumers know what was happening to the money they thought they spent to support the music they loved. As Glenn Peoples wrote last year (Fare Play: Could SoundCloud’s User-Centric Streaming Payouts Catch On?,
When Spotify first negotiated its initial licensing deals with labels in the late 2000s, both sides focused more on how much money the service would take in than the best way to divide it. The idea they settled on, which divides artist payouts based on the overall popularity of recordings, regardless of how they map to individuals’ listening habits, was ‘the simplest system to put together at the time,’ recalls Thomas Hesse, a former Sony Music executive who was involved in those conversations.
In other words, the market centric model was designed behind closed doors and then presented to the world’s artists and musicians as a take it or leave it with an overhyped helping of FOMO.
As we wrote in the WIPO study, the market centric model excludes nonfeatured musicians altogether. These studio musicians and vocalists are cut out of the Spotify streaming riches made off their backs except in two countries and then only because their unions fought like dogs to enforce national laws that require streaming platforms to pay nonfeatured performers.
The other Spotify problem is its global dominance and imposition of largely Anglo-American repertoire in other countries. The company does this for one big reason–they tell a growth story to Wall Street to juice their stock price. In fact, Daniel Ek just did this last week on his Groundhog Day earnings call with stock analysts. For example he said:
The number one thing that we’re stretched for at the moment is more inventory. And that’s why you see us introducing things such as fan and other things. And then long-term with a little bit more horizon, it’s obviously international.
Both user-centric and market-centric are focused on allocating a theoretical revenue “pie” which is so tiny for any one artist (or songwriter) who is not in the top 1 or 5 percent this week that it’s obvious the entire model is bankrupt until it includes the value that makes Daniel Ek into a digital munitions investor–the stock.
Debt and Stock Buybacks
Spotify has taken on substantial levels of debt for a company that makes a profit so infrequently you can say Spotify is unprofitable–which it is on a fully diluted basis in any event. According to its most recent balance sheet, Spotify owes approximately $1.3 billion in long term–secured–debt.
You might ask how a company that has never made a profit qualifies to borrow $1.3 billion and you’d have a point there. But understand this: If Spotify should ever go bankrupt, which in their case would probably be a reorganization bankruptcy, those lenders are going to stand in the secured creditors line and they will get paid in full or nearly in full well before Spotify meets any of its obligations to artists, songwriters, labels and music publishers, aka unsecured creditors.
Did Title I of the Music Modernization Act take care of this exposure for songwriters who are forced to license but have virtually no recourse if the licensee fails to pay and goes bankrupt? Apparently not–but then the lobbyists would say if they’d insisted on actual protection and reform there would have been no bill (pka no bonus).
Right. Because “modernization” (whatever that means).
But to our question here–is it ethical for a company that is totally dependent on creator output to be able to take on debt that pushes the royalties owed to those creators to the back of the bankruptcy lines? I think the answer is no.
Spotify has also engaged in a practice that has become increasingly popular in the era of zero interest rates (or lower bound rates anyway) and quantitative easing: stock buy backs.
Stock buy backs were illegal until the Securities and Exchange Commission changed the law in 1982 with the safe harbor Rule 10b-18. (A prime example of unelected bureaucrats creating major changes in the economy, but that’s a story for another day.)
Stock buy backs are when a company uses the shareholders money to buy outstanding shares of their company and reduce the number of shares trading (aka “the float”). Stock buy backs can be accomplished a few ways such as through a tender offer (a public announcement that the company will buy back x shares at $y for z period of time); open market purchases on the exchange; or buying the shares through direct negotiations, usually with holders of larger blocks of stock.
A stock buyback is basically a secondary offering in reverse — instead of selling new shares of stock to the public to put more cash on the corporate balance sheet, a cash-rich company expends some of its own funds on buying shares of stock from the public.
Why do companies buy back their own stock? To juice their financials by artificially increasing earnings per share.
Spotify has announced two different repurchase programs since going public according to their annual report for 12/31/21:
Share Repurchase Program On August 20, 2021, [Spotify] announced that the board of directors [controlled by Daniel Ek] had approved a program to repurchase up to $1.0 billion of the Company’s ordinary shares. Repurchases of up to 10,000,000 of the Company’s ordinary shares were authorized at the Company’s general meeting of shareholders on April 21, 2021. The repurchase program will expire on April 21, 2026. The timing and actual number of shares repurchased depends on a variety of factors, including price, general business and market conditions, and alternative investment opportunities. The repurchase program is executed consistent with the Company’s capital allocation strategy of prioritizing investment to grow the business over the long term. The repurchase program does not obligate the Company to acquire any particular amount of ordinary shares, and the repurchase program may be suspended or discontinued at any time at the Company’s discretion. The Company uses current cash and cash equivalents and the cash flow it generates from operations to fund the share repurchase program.
The authorization of the previous share repurchase program, announced on November 5, 2018, expired on April 21, 2021. The total aggregate amount of repurchased shares under that program was 4,366,427 for a total of approximately $572 million.
Is it ethical to take a billion dollars and buy back shares to juice the stock price while fighting over royalties every chance they get and crying poor?
I think not.
Spotify’s ESG Fail: Governance
Spotify has one big governance problem that permeates its governance like a putrid miasma in the abattoir: “Dual-class stock” sometimes referred to as “supervoting” stock. If you’ve never heard the term, buckle up. I wrote an extensive post on this subject for the New York Daily News that you may find interesting.
Dual class stock allows the holders of those shares–invariably the founders of the public company when it was a private company–to control all votes and control all board seats. Frequently this is accomplished by giving the founders a special class of stock that provides 10 votes for every share or something along those lines. The intention is to give the founders dead hand control over their startup in a kind of corporate reproductive right so that no one can interfere with their vision as envoys of innovation sent by the Gods of the Transhuman Singularity. You know, because technology.
Google was one of the first Silicon Valley startups to adopt this capitalization structure and it is consistent with the Silicon Valley venture capital investor belief in infitilism and the Peter Pan syndrome so that the little children may guide us. The problem is that supervoting stock is forever, well after the founders are bald and porky despite their at-home beach volleyball courts and warmed bidets.
Spotify, Facebook and Google each have a problem with “dual class” stock capitalizations. Because regulators allow these companies to operate with this structure favoring insiders, the already concentrated streaming music industry is largely controlled by Daniel Ek, Sergey Brin, Larry Page and Mark Zuckerberg. (While Amazon and Apple lack the dual class stock structure, Jeff Bezos has an outsized influence over both streaming and physical carriers. Apple’s influence is far more muted given their refusal to implement payola-driven algorithmic enterprise playlist placement for selection and rotation of music and their concentration on music playback hardware.)
The voting power of Ek, Brin, Page and Zuckerberg in their respective companies makes shareholder votes candidates for the least suspenseful events in commercial history. However, based on market share, Spotify essentially controls the music streaming business. Let’s consider some of the implications for competition of this disfavored capitalization technique.
Commissioner Robert Jackson, formerly of the U.S. Securities and Exchange Commission, summed up the problem:
“[D]ual class” voting typically involves capitalization structures that contain two or more classes of shares—one of which has significantly more voting power than the other. That’s distinct from the more common single-class structure, which gives shareholders equal equity and voting power. In a dual-class structure, public shareholders receive shares with one vote per share, while insiders receive shares that empower them with multiple votes. And some firms [Snap, Inc. and Google Class B shares] have recently issued shares that give ordinary public investors no vote at all.
For most of the modern history of American equity markets, the New York Stock Exchange did not list companies with dual-class voting. That’s because the Exchange’s commitment to corporate democracy and accountability dates back to before the Great Depression. But in the midst of the takeover battles of the 1980s, corporate insiders “who saw their firms as being vulnerable to takeovers began lobbying [the exchanges] to liberalize their rules on shareholder voting rights.” Facing pressure from corporate management and fellow exchanges, the NYSE reversed course, and today permits firms to go public with structures that were once prohibited.
Spotify is the dominant streaming firm and the voting power of Spotify stockholders is concentrated in two men: Daniel Ek and Martin Lorentzon. Transitively, those two men literally control the music streaming sector through their voting shares, are extending their horizontal reach into the rapidly consolidating podcasting business and aspire soon to enter the audiobooks vertical. Where do they get the money is a question on every artists lips after hearing the Spotify poormouthing and seeing their royalty statements.
The effects of that control may be subtle; for example, Spotify engages in multi-billion dollar stock buybacks and debt offerings, but has yet makes ever more spectacular losses while refusing to exercise pricing power.
So yes, Spotify is starting to look like the kind of Potemkin Village that investment bankers love because they see oodles of the one thing that matters: Fees.
On the political side, let’s see what the company’s campaign contributions tell us:
Spotify has also made a habit out of hiring away government regulators like Regan Smith, the former General Counsel and Associate Register of the US Copyright Office who joined Spotify as head of US public policy (a euphemism for bag person) after drafting all of the regulations for the Mechanical Licensing Collective;
Whether this is enough to trip Spotify up on the abuse of political contributions I don’t know, but the revolving door part certainly does call into question Spotify’s ethics.
It does seem that these are the kinds of facts that should be taken into account when determining Spotify’s ESG score.
What about the SEC investigation?
I suppose time will tell how the SEC handles its announced investigations into ESG “violations” whatever those might be (particularly in light of the SCOTUS West Virginia v. EPA holding and other “major questions” rulings recently).
There is a drumbeat starting in some quarters, particularly in the UK, for the government to inject itself into private contracts and cause a forgiveness of unrecouped balances in artist agreements after a date certain–as if by magic. Adopting such a law would focus Government action to essentially cause a compulsory “sale” by the government of the amount of every artist’s unrecouped balance due to the passing of time for what is arguably a private benefit.
Writing off the unrecouped balance for the artist’s private benefit would essentially cause the transfer to the artist of the value of the unrecouped balance to be measured at zero–which raises a question as to the other side of the double-entry if the government also allows a financial accounting write off for the record company investor but values that risk capital at zero. Government action of this type raises Constitutional questions in the U.S., and I suspect will also raise those same types of questions in any jurisdiction where the common law obtains. We’ll come back to this. It also raises questions as to why anyone would risk the investment in new artists’ recordings if the time frame for recovery of that risk capital is foreshortened. We’ll come back to this, too.
What’s Wrong with Being Unrecouped?
Remember—being unrecouped is not a “debt” or a “loan”. It’s just a prepayment of royalties by contract that is conditioned on certain events happening before it is ever “repaid.” There is no guarantee that the prepaid royalties will ever be earned.
One of the all-time great artist managers told me once that if his artist was recouped under the artist’s record deal, the manager was not doing his job. The whole point was to be as unrecouped as humanly possible at all times. Why? Because it was free money money bet that may never be called. Plus he would do his best to make the label or publisher bet too high and he was never going to let them bet too low.
Another great artist manager who was representing a new artist who went on to do well before breaking up said that once he realized he was never going to be recouped with the record company it was a wonderfully liberating experience. He’d talk them into loads of recoupable off-contract payments like tour support, promotion and marketing that made his band successful and that he didn’t share with the label. Tour support is only 50% recoupable? How much will you spend if it’s 100% recoupable?
Get the idea? We’re starting to hear some rumblings about a statutory cutoff for recoupment of a term of years. First of all, I would bet such a rule in the U.S. if applied retroactively would be unconstitutional taking in violation of due process under the 5th Amendment. Regardless, whichever country adopts such a rule will in short order find themselves with either no record companies or with vastly different deal points in artist recording agreements subject to their national law. (See the “$50,000 a year” controversy from 1994 over California Civ. Code §3423 when California-based labels were contemplating leaving the State. We’re way beyond runaway production now.)
Record Company as Banker
Let’s imagine two scenarios: One is an unsigned artist trying to finance a recording, the other is a catalog artist with an inactive royalty account. They each illustrate different issues regarding recoupment.
Imagine you went to a bank to finance your recordings. You told the banker I do some livestreams, here’s my Venmo account statements and I have all this Spotify data on my 200,000 streams that made me $500 but cost me $10,000 in marketing. Most importantly of all, your assistant thinks I am really cool, if you catch my drift.
I want to make a better record and I think I could get some gigs if clubs ever reopen. My songs are really cool. I need you to lend me $50,000 to make my record and another $50,000 to market it. (Probably way more.) I don’t want a maturity date on the loan, I don’t want events of default (meaning it is “non recourse”), you can’t charge me interest, I don’t want to make payments, but you can recoup the principal from the earnings I make for licensing or selling copies of the recordings you pay for. I’ll market those recordings unless my band breaks up which you have no control over. As I recoup the principal, I’ll pay you in current dollars for the historical unrecouped balance. I keep all the publishing, merch and live. And oh, if you want you can own the recordings, but understand that I will be doing everything I can to try to get you (or guilt you or force you) to give me the recordings back regardless of whether you have recouped your “loan” which isn’t a loan at all.
Deal?
Catalog Fairness
Then consider a catalog artist. The catalog artist was signed 25 years ago to a term recording artist agreement with $500,000 per LP on a three firm agreement that didn’t pan out. After tour support, promotion, additional advances to cover income tax payments, the artist got dropped from their label and broke up with a $1,000,000 unrecouped balance. In the intervening years, the artists went on to individual careers as songwriters and film composers, but none of those subsequent earnings were recoupable as they got dropped and were under separate contracts. Another thing that happened in the intervening years was the label went from selling CDs at a $10 wholesale price through their wholly owned branch distribution system to selling streams at $0.003 each through a third party platform with probably triple the marketing costs.
The old recordings eventually dwindled below 1,500 CD units a year for a few years, and in 2005 the label cut them out, but continued to service their digital accounts with the recordings as deep and ever deeper catalog. After a few sync placements, earnings reached zero for a couple years and the royalty account was archived, i.e., taken off line. Streaming happened and now the recordings are making about $100 a year until one track got onto a Spotify “Gen Z Afternoon Safe Space Tummy Rub” playlist and scored 1,000,000 streams or about $600 give or take. When the royalty account was archived, it had an unrecouped balance of $800,000 in 1995 dollars. So the $600 gets accrued in case the catalog ever earns enough to justify the cost of reactivating the account—which means the artist doesn’t get paid for the recordings because they are unrecouped but they also don’t get a statement because they’ve had an earnings drought. Like most per-stream payments, it would cost more to account for the $600 on a statement than the royalties payable.
Bear in mind that adjusted for inflation—and we’ll come back to that—the $800,000 in 1995 dollars would be worth $1,366,866.14 today. But because the record company does not charge either overhead, interest, or any inflation charge, the historical $800,000 from 1995 is paid off in ever-inflated current dollars.
As the artist managers said, the artists long ago got the benefit of getting essentially a no-risk lifetime royalty pre-payment (it’s not really correct to call it a “loan” when there’s no recourse, maturity date, payments, interest rate or repayment schedule) and long ago spent the money on a variety of business and personal expenses. Which potentially enhanced their careers so they could get that film work later down the line. Or more simply, a bird in the hand.
Do You Really Want Monkey Points?
If you want to see what would happen if this apple cart were rocked, take a good look at a good corollary, the “net profits” definition in the film business, or what Eddy Murphy famously called “monkey points.” Without getting into the gory details, studios will typically play a game with gross receipts that involves exclusions, deductions, subdistributor receipts, advances, ancillary rights, income from physical properties (from memorabilia like Dorothy’s slippers), distribution fees, distribution and marketing expenses, deferments, gross participation, negative costs, interest on the negative cost, overbudget deductions, overhead on negative cost and marketing costs (and interest on overhead)…shall I go on? And then there’s the accounting.
The movie industry also has a concept called “turnaround”. Turnaround happens when Studio A decides (usually for commercial reasons) it is not going forward with a script that it has developed and offers it to other studios for a price that allows it to recover some or all of its development costs usually with an override royalty. Sometimes it works out well–after a very long time, the project may become “ET.” Would artists prefer getting dropped or having their contracts put into turnaround?
The point is that while it may sound good to make unrecouped balances vanish after a date certain, people who say that seem to think that all the other deal terms will stay constant or even improve for the artists after that substantial risk shifting. I seriously doubt that, just like I doubt that venture capitalists who fund the startups that bag on record companies would give up their 2 or 3x liquidation preference, full ratchet anti-dilution protection, registration rights or co-sale agreements.
Should 5% Appear Too Small
But did the unrecouped balance actually vanish? Not really. The value was transferred to the artist in the form of forgiveness of an obligation for the artist’s private benefit, however contingent. That value may be measured in an amount greater than the historic unrecouped balance. Is this value transfer a separate taxable event? Must the artist declare the forgiveness as income? Can the record company write off the value transferred as a loss? If not, why not? I can’t think of a good reason. If anything, valuing the “taking” in current dollars would only correct the valuation issue and could amplify the tax liability of the transfer.
As you can see, wiping out unrecouped balances sounds easy until you think about it. It is actually a rather complex transaction which immediately raises another question as to when it stops. Why just signed artists? Why not all artists? Songwriters? Profit participants in motion pictures or television? Authors? All of this will be taken into account.
King John and the Barons: Don’t Tread On Me
Setting aside the tax implication, were such government action to take the form of a law to be enacted in the United States, it would prohibit a fundamental right previously enjoyed under the 5th Amendment to the U.S. Constitution (one of the Amendments known as the “Bill of Rights”). The “takings” clause of the 5th Amendment states “…nor shall private property be taken for public use, without just compensation.” In fact, such government action would implicate the fundamental rights expressed in the 5th Amendment and applied against the states in the 14th Amendment to the Constitution. The 5th Amendment derives from Section 39 of Magna Carta, the seminal constitutional documents in the United Kingdom (dating from 1215 for those reading along at home) and was central to the thinking of Coke, Blackstone and Locke who were central to the thinking of the Founders.
In the U.S., such a law would likely be given a once over and strictly scrutinized by the courts (including The Court) to determine if taking unrecouped balances from a select group of artists, i.e., those signed to record companies, is the only way to get at a compelling government interest in promoting culture even though the taking would be pretty obviously for the private benefit of the artists concerned and only benefiting the public in a very attenuated manner. In other words, will treating a select group of pretty elite artists (at a minimum those signed vs. those unsigned) satisfy the strict scrutiny standard applied to a government taking of private property with no compensation. (This distinction also smacks of a due process violation which is a whole other rabbit hole.) I suspect the government loses the strict scrutiny microbial scrub and will be required to compensate the record company for the taking at the fair market value of the unrecouped balances.
Because I think this is pretty clearly a total regulatory taking that is a per se violation of the 5th Amendment, I suspect that a court (or the Supreme Court) would be inclined to hold the law invalid on Constitutional grounds and simply stop any enforcement.
Failing that strict scrutiny standard, a court could ask if the zeroing of unrecouped balances with no compensation is rationally related to a legitimate government interest. I still think that the taking would fail in this case as there a many other ways for the government to promote culture and even to encourage labels to voluntarily wipe out the unrecouped balances at some point such as through a quid pro quo of favorable tax treatment, changing the accounting rules or offsets of one kind or another on the sale of a catalog.
Running for the Exits
If anything, I think that government acting to cut off the ability to recoup at a date certain with no compensation (which sure sounds like an unconstitutional taking in the US) would necessarily make labels start thinking about compensating for that taking by moving out of those territories where it is given effect (or at least not signing artists from those countries). Such moves might make artists start thinking about moving to where they could get signed.
Or worse yet, it would make labels re-think their financial terms and re-recording restrictions. Overhead charges and interest on recording costs would be two changes I would expect to see almost immediately. And that would be a poor trade off.
Iterative Government Choices
The choice that artists make is whether to sign up to an investor like a record company who wants a long-term recoupment relationship against pre-paid royalties. If you don’t like a place, don’t go there and if you don’t like the deal, don’t sign.
Any government that contemplates taking unrecouped balances must necessarily also contemplate offering artists grants to make up the shortfall due to signing contractions. This could include for example the host of grant funding sources available in Canada such as FACTOR and the many provincial music grants. And those grants should not come from the black box thank you very much.
On the other hand, I do see a lot of fairness in requiring on-demand services to pay featured and nonfeatured artists a kind of equitable remuneration like webcasters and satellite radio do, which is paid through on a nonrecoupment basis directly to the artists in the US. While they may criticize the system that produced the recordings that have made them rich beyond the wildest dreams of artists, songwriters or music executives (except the ones the services hire away), that doesn’t mean that they shouldn’t pay over to creators some of the valuation transfer that made Daniel Ek a multibillionaire while artists get less than ½¢ per stream.
So the takeaways here are:
Wiping out unrecouped balances with no compensation is likely illegal.
Creating a meaningful and attractive tax incentive for record companies to wipe out an unrecouped balance conditioned on that benefit being passed through to artists is worth exploring. (Why wait 15 years to give that effect?) This may be particularly attractive in a time of rising taxable income at labels.
Requiring the services to pay a royalty in the nature of equitable remuneration on a nonrecoupment basis is a way to grow the pie and get some relief to both featured and nonfeatured artists. This new stream is also worth exploring.
Livestreaming was intended to be temporary. It was a bridge between a pre and post COVID reality. But it’s not. The biggest of Big Tech companies intend it to be permanent and they mean to control it. And you have to believe that a very high percentage of venues may not be coming back.
Live music venues are closing permanently at a rapid clip. Cities like Austin and festivals like SXSW and ACL Fest are changed forever. We know that the real estate developers are licking their chops at the idea of dumping those live music venues and onboarding Uber Eats, Google, Facebook or something really important. (See “I Don’t Need Another Email Whining About COVID“) But they are not the only ones who have no intention of helping live music recover in a venue-free future.
Facebook/Instagram is probably leading the way on this Great Step Forward, followed closely by TikTok and of course YouTube. Facebook in particular is adopting policies to limit DJ-type listening parties on the platform. (This very well may backfire.) The elephant in the room is that Facebook seems to have gotten religion on music licensing after a 17 years growth binge of shredding artist rights. While asserting “You are responsible for the content you post” Facebook also tells us “Unauthorized content may be removed.” Why not track it and monetize it? Because they can’t be bothered. It does seem that Facebook intents to permit artist-branded live-streaming events which is nice of them, but it also seems like the new policy clears the way for Facebook to monetize live streaming events and take their cut.
It has become obvious that whenever audiences decide to come out of the lock down, there may not be any venues for them to go to. (Or restaurants for that matter.) As I have said almost from the beginning of the pandemic, Austin is about to become another college town with a Google/Facebook campus and the City government itself is just thrilled about that expanded tax base. Cynical? Not really. Spend a little time getting condescended to by the City of Austin and you will get the idea that they would just as soon that live music was in the rear view mirror. If that happens to Austin, which had styled itself as “The Live Music Capital of the World” to the great gnashing of teeth by almost every other sector starting with tech, it will happen in a host of cities around the world.
Of course Big Tech cannot be seen to be leading the charge to live music oblivion. That would be quite impolitic (if not actionable). But the vibe from governments in the erstwhile “music cities” like Austin, Denver, Seattle, and even San Francisco is similar to the efforts of Spotify, Facebook, Google & Co. to support the venues that create the value and the fan base that drives traffic to the live streams they think are the future. These politicians and Big Tech companies want to be seen to be helping, but not too much. They don’t want to help so much that most of the venues might actually recover.
Evidence? Talk to anyone at Facebook who has contact with artists and labels. (And if you ever wondered who doesn’t click “Skip Ads”, it’s them.)
Facebook certainly is building its “Stars” tip jar model that is in closed beta but will be rolled out soon. That’s partly because Facebook views live streaming as a permanent part of the data mining ecosystem that Facebook is uniquely positioned to control. Facebook Stars will prove to be a key component of the venue free future after the COVID and Facebook duo deliver the venue DNR. And in case you didn’t quite get how Facebook values music, a Star is worth 1¢. That’s right–one penny. (Which will make it easier to switch Stars scrip to Facebook Bucks aka Libra.)
Don’t forget, Tencent led the way on this “gifting” concept. Tencent allows users (all users, subscription or ad-supported service) to make virtual gifts in the form of micropayments directly to artists they love. (The feature is actually broader than cash and applies to all content creators, but let’s stay with socially-driven micropayments to artists or songwriters.)
Tencent, of course, makes serious bank on these system-wide micropayments. As Jim Cramer noted in “Mad Money” :
“Tencent Music is a major part of the micropayment ecosystem because they let you give virtual gifts,” Cramer said. “If you want to tip your favorite blogger with a song, you do it through Tencent Music. In the latest quarter we have numbers for, 9.5 million users spent money on virtual gifts, and these purchases accounted for more than 70 percent of Tencent Music’s revenue.”
And that’s real money. Tencent actually made this into a selling point in their IPO prospectus:
We are pioneering the way people enjoy online music and music-centric social entertainment services. We have demonstrated that users will pay for personalized, engaging and interactive music experiences. Just as we value our users, we also respect those who create music. This is why we champion copyright protection-because unless content creators are rewarded for their creative work, there won’t be a sustainable music entertainment industry in the long run. Our scale, technology and commitment to copyright protection make us a partner of choice for artists and content owners.
So in case you were wondering why we haven’t seen Big Tech really step up to contributing money to support venues in line with the value of the data they scrape from all the fans driven to live streaming, it’s because they don’t want live music venues to be sustainable. They’ve been trying to break down live music for a decade and the pandemic presented the disruption opportunity for them to actually do it.
Facebook and their counterparts are getting all kinds of free content (and the corollary free data) from desperate bands in the latest example of pandemic price gouging. Those desperate artists are now forced to consider the option of the Data Lords coin of the realm–advertising and brand integration. The effect may well be that the only artists who survive the venue DNR are those willing to take the King’s shilling. Welcome to the company store.
The Data Lords have finally found a way–fear of death–to get fans to substitute away from live music. There’s nothing quite as disruptive as the threat of dying. If you ever thought that the live experience was the last stronghold of authenticity against the onslaught of Silicon Valley disruption, you probably never thought that fear of mortality would drive the nail in the coffin of the backstage pass or burn the velvet rope. Stars in every pot and a drone-delivered Big Box on every doorstep.
But you’d be wrong. As we slip into the twilight days of live music and festivals, Facebook stands ready with their venue DNR orders. And live-streaming will be driven by desperation to be the Data Lords’ venue free meal ticket.
Why is this bad? Because if you talk to any of the label relations types at Facebook, Google or TikTok it is a name droppers paradise. They don’t really understand how to do the careful spadework that is necessary to break an artist to have an actual career. They have major artists handed to them after that work has already been done, and done long ago in many cases. There may be the odd “influencer” who gets a movie or a commercial, but the jury is out on whether these platforms can build careers. (Or whether there will be many movies for influencers to get a role in.)
Not so of venues. We know what they do and they’ve been doing it for a long, long time. But we have to face the harsh reality that unless something changes very quickly, the Data Lords may have just piggybacked the massive income transfer of their DMCA and 230 safe harbors into another takeover of our business. And they’ll do it in a way that could leave the entire live music economy and workers flopping like fish on a beach.