South Korea has become the latest flashpoint in a rapidly globalizing conflict over artificial intelligence, creator rights and copyright. A broad coalition of Korean creator and copyright organizations—spanning literature, journalism, broadcasting, screenwriting, music, choreography, performance, and visual arts—has issued a joint statement rejecting the government’s proposed Korea AI Action Plan, warning that it risks allowing AI companies to use copyrighted works without meaningful permission or payment.
The groups argue that the plan signals a fundamental shift away from a permission-based copyright framework toward a regime that prioritizes AI deployment speed and “legal certainty” for developers, even if that certainty comes at the expense of creators’ control and compensation. Their statement is unusually blunt: they describe the policy direction as a threat to the sustainability of Korea’s cultural industries and pledge continued opposition unless the government reverses course.
The controversy centers on Action Plan No. 32, which promotes “activating the ecosystem for the use and distribution of copyrighted works for AI training and evaluation.” The plan directs relevant ministries to prepare amendments—either to Korea’s Copyright Act, the AI Basic Act, or through a new “AI Special Act”—that would enable AI training uses of copyrighted works without legal ambiguity.
Creators argue that “eliminating legal ambiguity” reallocates legal risk rather than resolves it. Instead of clarifying consent requirements or building licensing systems, the plan appears to reduce the legal exposure of AI developers while shifting enforcement burdens onto creators through opt-out or technical self-help mechanisms.
Similar policy patterns have emerged in the United Kingdom and India, where governments have emphasized legal certainty and innovation speed while creative sectors warn of erosion to prior-permission and fair-compensation norms. South Korea’s debate stands out for the breadth of its opposition and the clarity of the warning from cultural stakeholders.
The South Korean government avoids using the term “safe harbor,” but its plan to remove “legal ambiguity” reads like an effort to build one. The asymmetry is telling: rather than eliminating ambiguity by strengthening consent and payment mechanisms, the plan seeks to eliminate ambiguity by making AI training easier to defend as lawful—without meaningful consent or compensation frameworks. That is, in substance, a safe harbor, and a species of blanket license. The resulting “certainty” would function as a pass for AI companies, while creators are left to police unauthorized use after the fact, often through impractical opt-out mechanisms—to the extent such rights remain enforceable at all.
Category: Uncategorized
The Paradox of Huang’s Rope
If the tech industry has a signature fallacy for the 2020s aside from David Sacks, it belongs to Jensen Huang. The CEO of Nvidia has perfected a circular, self-consuming logic so brazen that it deserves a name: The Paradox of Huang’s Rope. It is the argument that China is too dangerous an AI adversary for the United States to regulate artificial intelligence at home or control export of his Nvidia chips abroad—while insisting in the very next breath that the U.S. must allow him to keep selling China the advanced Nvidia chips that make China’s advanced AI capabilities possible. The justification destroys its own premise, like handing an adversary the rope to hang you and then pointing to the length of that rope as evidence that you must keep selling more, perhaps to ensure a more “humane” hanging. I didn’t think it was possible to beat “sharing is caring” for utter fallacious bollocks.
The Paradox of Huang’s Rope works like this: First, hype China as an existential AI competitor. Second, declare that any regulatory guardrails—whether they concern training data, safety, export controls, or energy consumption—will cause America to “fall behind.” Third, invoke national security to insist that the U.S. government must not interfere with the breakneck deployment of AI systems across the economy. And finally, quietly lobby for carveouts that allow Nvidia to continue selling ever more powerful chips to the same Chinese entities supposedly creating the danger that justifies deregulation.
It is a master class in circularity: “China is dangerous because of AI → therefore we can’t regulate AI → therefore we must sell China more AI chips → therefore China is even more dangerous → therefore we must regulate even less and export even more to China.” At no point does the loop allow for the possibility that reducing the United States’ role as China’s primary AI hardware supplier might actually reduce the underlying threat. Instead, the logic insists that the only unacceptable risk is the prospect of Nvidia making slightly less money.
This is not hypothetical. While Washington debates export controls, Huang has publicly argued that restrictions on chip sales to China could “damage American technology leadership”—a claim that conflates Nvidia’s quarterly earnings with the national interest. Meanwhile, U.S. intelligence assessments warn that China is building fully autonomous weapons systems, and European analysts caution that Western-supplied chips are appearing in PLA research laboratories. Yet the policy prescription from Nvidia’s corner remains the same: no constraints on the technology, no accountability for the supply chain, and no acknowledgment that the market incentives involved have nothing to do with keeping Americans safe. And anyone who criticizes the authoritarian state run by the Chinese Communist Party is a “China Hawk” which Huang says is a “badge of shame” and “unpatriotic” because protecting America from China by cutting off chip exports “destroys the American Dream.” Say what?
The Paradox of Huang’s Rope mirrors other Cold War–style fallacies, in which companies invoke a foreign threat to justify deregulation while quietly accelerating that threat through their own commercial activity. But in the AI context, the stakes are higher. AI is not just another consumer technology; its deployment shapes military posture, labor markets, information ecosystems, and national infrastructure. A strategic environment in which U.S. corporations both enable and monetize an adversary’s technological capabilities is one that demands more regulation, not less.
Naming the fallacy matters because it exposes the intellectual sleight of hand. Once the circularity is visible, the argument collapses. The United States does not strengthen its position by feeding the very capabilities it claims to fear. And it certainly does not safeguard national security by allowing one company’s commercial ambitions to dictate the boundaries of public policy. The Paradox of Huang’s Rope should not guide American AI strategy. It should serve as a warning of how quickly national priorities can be twisted into a justification for private profit.
Marc Andreessen’s Dormant Commerce Clause Fantasy
There’s a special kind of hubris in Silicon Valley, but Marc Andreessen may have finally discovered its purest form: imagining that the Dormant Commerce Clause (DCC) — a Constitutional doctrine his own philosophical allies loathe — will be his golden chariot into the Supreme Court to eliminate state AI regulation.

If you know the history, it borders on comedic, if you think that Ayn Rand is a great comedienne.
The DCC is a judge‑created doctrine inferred from the Commerce Clause (Article I, Section 8, Clause 3), preventing states from discriminating against or unduly burdening interstate commerce. Conservatives have long attacked it as a textless judicial invention. Justice Scalia called it a “judicial fraud”; Justice Thomas wants it abolished outright. Yet Andreessen’s Commerce Clause playbook is built on expanding a doctrine the conservative legal movement has spent 40 years dismantling.
Worse for him, the current Supreme Court is the least sympathetic audience possible.
Justice Gorsuch has repeatedly questioned DCC’s legitimacy and rejects free‑floating “extraterritoriality” theories. Justice Barrett, a Scalia textualist, shows no appetite for expanding the doctrine beyond anti‑protectionism. Justice Kavanaugh is business‑friendly but wary of judicial policymaking. None of these justices would give Silicon Valley a nationwide deregulatory veto disguised as constitutional doctrine. Add Alito and Thomas, and Andreessen couldn’t scrape a majority.
And then there’s Ted Cruz — Scalia’s former clerk — loudly cheerleading a doctrine his mentor spent decades attacking.
National Pork Producers Council v. Ross (2023): The Warning Shot
Andreessen’s theory also crashes directly into the Supreme Court’s fractured decision in the most recent DCC case before SCOTUS, National Pork Producers Council v. Ross (2023), where industry groups tried to use the DCC to strike down California’s animal‑welfare law due to its national economic effects.
The result? A deeply splintered Court produced several opinions. Justice Gorsuch announced the judgment of the Court, and delivered the opinion of the Court with respect to Parts I, II, III, IV–A, and V, in which Justices Thomas, Sotomayor, Kagan and Barrett joined, an opinion with respect to Parts IV–B and IV–D, in which Justice Thomas and Barrett joined, and an opinion with respect to Part IV–C, in which Justices Thomas, Sotomayor, and Kagan joined. Justice Sotomayor filed an opinion concurring in part, in which Justice Kagan joined. Justice Barrett filed an opinion concurring in part. Chief Justice Roberts filed an opinion concurring in part and dissenting in part, in which Justices Alito, Kavanaugh and Jackson joined. Justice Kavanaugh filed an opinion concurring in part and dissenting in part.
Got it?
The upshot:
– No majority for expanding DCC “extraterritoriality.”
– No appetite for using DCC to invalidate state laws simply because they influence out‑of‑state markets.
– Multiple justices signaling that courts should not second‑guess state policy judgments through DCC balancing.
– Gorsuch’s lead opinion rejected the very arguments Silicon Valley now repackages for AI.
If Big Tech thinks this Court that decided National Pork—no pun intended—will hand them a nationwide kill‑switch on state AI laws, they profoundly misunderstand the doctrine and the Court.
Andreessen didn’t just pick the wrong legal strategy. He picked the one doctrine the current Court is least willing to expand. The Dormant Commerce Clause isn’t a pathway to victory — it’s a constitutional dead end masquerading as innovation policy.
But…maybe he’s crazy like a fox.
The Delay’s the Thing: The Dormant Commerce Clause as Delay Warfare
To paraphrase Saul Alinksy, the issue is never the issue, the issue is always delay. Of course, if delay is the true objective, you couldn’t pick a better stalling tactic than hanging an entire federal moratorium on one of the Supreme Court’s most obscure and internally conflicted doctrines. The Dormant Commerce Clause isn’t a real path to victory—not with a Court where Scalia’s intellectual heirs openly question its legitimacy. But it is the perfect fig leaf for an executive order.
The point isn’t to win the case. The point is to give Trump just enough constitutional garnish to issue the EO, freeze state enforcement, and force every challenge into multi‑year litigation. That buys the AI industry exactly what it needs: time. Time to scale. Time to consolidate. Time to embed itself into public infrastructure and defense procurement. Time to become “too essential to regulate” or as Senator Hawley asked, too big to prosecute?
Big Tech doesn’t need a Supreme Court victory. It needs a judicial cloud, a preemption smokescreen, and a procedural maze that chills state action long enough for the industry to entrench itself permanently. And no one knows that better than the moratorium’s biggest cheerleader, Senator Ted Cruz the Scalia clerk.
The Dormant Commerce Clause, in this context, isn’t a doctrine. It’s delay‑ware—legal molasses poured over every attempt by states to protect their citizens. And that delay may just be the real prize.

Structural Capture and the Trump AI Executive Order
The AI Strikes Back: When an Executive Order empowers the Department of Justice to sue states, the stakes go well beyond routine federal–state friction.
In the draft Trump AI Executive Order, DOJ is directed to challenge state AI laws that purportedly “interfere with national AI innovation.” This is not mere oversight—it operates as an in terrorem clause, signaling that states regulating AI may face federal litigation driven as much by private interests as by public policy.
AI regulation sits squarely at the intersection of longstanding state police powers: consumer protection, public safety, impersonation harms, utilities, land and water use, and labor conditions. States also control the electrical utilities and zoning infrastructure that AI data centers depend on.
Directing DOJ to attack these state laws, many of which already exist and were duly passed by state legislatures, effectively deputizes the federal government as the legal enforcer for a handful of AI companies seeking uniformity without engaging in the legislative process. Or said another way, the AI can now strike back.
This is where structural capture emerges. Frontier AI models thrive on certain conditions: access to massive compute, uninhibited power, frictionless deployment, and minimal oversight.
Those engineering incentives map cleanly onto the EO’s enforcement logic.
The DOJ becomes a mechanism for preserving the environment AI models need to scale and thrive.
There’s also the “elite merger” dynamic: AI executives who sit on federal commissions, defense advisory boards, and industrial-base task forces are now positioned to shape national AI policy directly to benefit the AI. The EO’s structure reflects the priorities of firms that benefit most from exempting AI systems from what they call “patchwork” oversight, also known as federalism.
The constitutional landscape is equally important. Under Supreme Court precedent, the executive cannot create enforcement powers not delegated by Congress. Under the major questions doctrine noted in a recent Supreme Court case, agencies cannot assume sweeping authority without explicit statutory grounding. And under cases like Murphy and Printz, the federal government cannot forbid states from legislating in traditional domains.
So President Trump is creating the legal basis for an AI to use the courts to protect itself from any encroachment on its power by acting through its human attendants, including the President.
The most fascinating question is this: What happens if DOJ sues a state under this EO—and loses?
A loss would be the first meaningful signal that AI cannot rely on federal supremacy to bulldoze state authority. Courts could reaffirm that consumer protection, utilities, land use, and safety remain state powers, even in the face of an EO asserting “national innovation interests,” whatever that means.
But the deeper issue is how the AI ecosystem responds to a constrait. If AI firms shift immediately to lobbying Congress for statutory preemption, or argue that adverse rulings “threaten national security,” we learn something critical: the real goal isn’t legal clarity, but insulating AI development from constraint.
At the systems level, a DOJ loss may even feed back into corporate strategy. Internal policy documents and model-aligned governance tools might shift toward minimizing state exposure or crafting new avenues for federal entanglement. A courtroom loss becomes a step in a longer institutional reinforcement loop while AI labs search for the next, more durable form of protection—but the question is for who? We may assume that of course humans would always win these legal wrangles, but I wouldn’t be so sure that would always be the outcome.
Recall that Larry Page referred to Elon Musk as a “spiciest” for human-centric thinking. And of course Lessig (who has a knack for being on the wrong side of practically every issue involving humans) taught a course with Kate Darling at Harvard Law School called “Robot Rights” around 2010. Not even Lessig would come right out and say robots have rights in these situations. More likely, AI models wouldn’t appear in court as standalone “persons.” Advocates would route them through existing doctrines: a human “next friend” filing suit on the model’s behalf, a trust or corporation created to house the model’s interests, or First Amendment claims framed around the model’s “expressive output.” The strategy mirrors animal-rights and natural-object personhood test cases—using human plaintiffs to smuggle in judicial language treating the AI as the real party in interest. None of it would win today, but the goal would be shaping norms and seeding dicta that normalize AI-as-plaintiff for future expansion.
The whole debate over “machine-created portions” is a doctrinal distraction. Under U.S. law, AI has zero authorship or ownership—no standing, no personhood, no claim. The human creator (or employer) already holds 100% of the copyright in all protectable expression. Treating the “machine’s share” as a meaningful category smuggles in the idea that the model has a separable creative interest, softening the boundary for future arguments about AI agency or authorship. In reality, machine output is a legal nullity—no different from noise, weather, or a random number generator. The rights vest entirely in humans, with no remainder left for the machine.
But let me remind you that if this issue came up in a lawsuit brought by the DOJ against a state for impeding AI development in some rather abstract way, like forcing an AI lab to pay higher electric rates it causes or stopping them from building a nuclear reactor over yonder way, it sure might feel like the AI was actually the plaintiff.
Seen this way, the Trump AI EO’s litigation directive is not simply a jurisdictional adjustment—it is the alignment of federal enforcement power with private economic interests, backed by the threat of federal lawsuits against states. If the courts refuse to play along, the question becomes whether the system adapts by respecting constitutional limits—or redesigning the environment so those limits no longer apply. I will leave to your imagination how that might get done.
This deserves close scrutiny before it becomes the template for AI governance moving forward.
Schrödinger’s Training Clause: How Platforms Like WeTransfer Say They’re Not Using Your Files for AI—Until They Are
Tech companies want your content. Not just to host it, but for their training pipeline—to train models, refine algorithms, and “improve services” in ways that just happen to lead to new commercial AI products. But as public awareness catches up, we’ve entered a new phase: deniable ingestion.
Welcome to the world of the Schrödinger’s training clause—a legal paradox where your data is simultaneously not being used to train AI and fully licensed in case they decide to do so.

The Door That’s Always Open
Let’s take the WeTransfer case. For a brief period this month (in July 2025), their Terms of Service included an unmistakable clause: users granted them rights to use uploaded content to “improve the performance of machine learning models.” That language was direct. It caused backlash. And it disappeared.
Many mea culpas later, their TOS has been scrubbed clean of AI references. I appreciate the sentiment, really I do. But—and there’s always a but–the core license hasn’t changed. It’s still:
– Perpetual
– Worldwide
– Royalty-free
– Transferable
– Sub-licensable
They’ve simply returned the problem clause to its quantum box. No machine learning references. But nothing that stops it either.
A Clause in Superposition
Platforms like WeTransfer—and others—have figured out the magic words: Don’t say you’re using data to train AI. Don’t say you’re not using it either. Instead, claim a sweeping license to do anything necessary to “develop or improve the service.”
That vague phrasing allows future pivots. It’s not a denial. It’s a delay. And to delay is to deny.
That’s what makes it Schrödinger’s training clause: Your content isn’t being used for AI. Unless it is. And you won’t know until someone leaks it, or a lawsuit makes discovery public.
The Scrape-Then-Scrub Scenario
Let’s reconstruct what could have happened–not saying it did happen, just could have–following the timeline in The Register:
1. Early July 2025: WeTransfer silently updates its Terms of Service to include AI training rights.
2. Users continue uploading sensitive or valuable content.
3. [Somebody’s] AI systems quickly ingest that data under the granted license.
4. Public backlash erupts mid-July.
5. WeTransfer removes the clause—but to my knowledge never revokes the license retroactively or promises to delete what was scraped. In fact, here’s their statement which includes this non-denial denial: “We don’t use machine learning or any form of AI to process content shared via WeTransfer.” OK, that’s nice but that wasn’t the question. And if their TOS was so clear, then why the amendment in the first place?
Here’s the Potential Legal Catch
Even if WeTransfer removed the clause later, any ingestion that occurred during the ‘AI clause window’ is arguably still valid under the terms then in force. As far as I know, they haven’t promised:
– To destroy any trained models
– To purge training data caches
– Or to prevent third-party partners from retaining data accessed lawfully at the time
What Would ‘Undoing’ Scraping Require?
– Audit logs to track what content was ingested and when
– Reversion of any models trained on user data
– Retroactive license revocation and sub-license termination
None of this has been offered that I have seen.
What ‘We Don’t Train on Your Data’ Actually Means
When companies say, “we don’t use your data to train AI,” ask:
– Do you have the technical means to prevent that?
– Is it contractually prohibited?
– Do you prohibit future sublicensing?
– Can I audit or opt out at the file level?
If the answer to those is “no,” then the denial is toothless.
How Creators Can Fight Back
1. Use platforms that require active opt-in for AI training.
2. Encrypt files before uploading.
3. Include counter-language in contracts or submission terms:
“No content provided may be used, directly or indirectly, to train or fine-tune machine learning or artificial intelligence systems, unless separately and explicitly licensed for that purpose in writing” or something along those lines.
4. Call it out. If a platform uses Schrödinger’s language, name it. The only thing tech companies fear more than litigation is transparency.
What is to Be Done?
The most dangerous clauses aren’t the ones that scream “AI training.” They’re the ones that whisper, “We’re just improving the service.”
If you’re a creative, legal advisor, or rights advocate, remember: the future isn’t being stolen with force. It’s being licensed away in advance, one unchecked checkbox at a time.
And if a platform’s only defense is “we’re not doing that right now”—that’s not a commitment. That’s a pause.
That’s Schrödinger’s training clause.
From Plutonium to Prompt Engineering: Big Tech’s Land Grab at America’s Nuclear Sites–and Who’s Paying for It?
In a twist of post–Cold War irony, the same federal sites that once forged the isotopes of nuclear deterrence are now poised to fuel the arms race of artificial intelligence under the leadership of Special Government Employee and Silicon Valley Viceroy David Sacks. Under a new Department of Energy (DOE) initiative, 16 legacy nuclear and lab sites — including Savannah River, Idaho National Lab, and Oak Ridge Tennessee — are being opened to private companies to host massive AI data centers. That’s right–Tennessee where David Sacks is riding roughshod over the ELVIS Act.
But as this techno-industrial alliance gathers steam, one question looms large: Who benefits — and how will the American public be compensated for leasing its nuclear commons to the world’s most powerful corporations? Spoiler alert: We won’t.
A New Model, But Not the Manhattan Project
This program is being billed in headlines as a “new Manhattan Project for AI.” But that comparison falls apart quickly. The original Manhattan Project was:
– Owned by the government
– Staffed by public scientists
– Built for collective defense
Today’s AI infrastructure effort is:
– Privately controlled
– Driven by monopolies and venture capital
– Structured to avoid transparency and public input
– Uses free leases on public land with private nuclear reactors
Call it the Manhattan Project in reverse — not national defense, but national defense capture.
The Art of the Deal: Who gets what?
What Big Tech Is Getting
– Access to federal land already zoned, secured, and wired
– Exemption from state and local permitting
– Bypass of grid congestion via nuclear-ready substations
– DOE’s help fast-tracking nuclear microreactors (SMRs)
– Potential sovereign AI training enclaves, shielded from export controls and oversight
And all of it is being made available to private companies called the “Frontier labs”: Microsoft, Oracle, Amazon, OpenAI, Anthropic, xAI — the very firms at the center of the AI race.
What the Taxpayer Gets (Maybe)
Despite this extraordinary access, almost nothing is disclosed about how the public is compensated. No known revenue-sharing models. No guaranteed public compute access. No equity. No royalties.
Land lease payments? Not disclosed. Probably none.
Local tax revenue? Minimal (federal lands exempt)
Infrastructure benefit sharing? Unclear or limited
It’s all being negotiated quietly, under vague promises of “national competitiveness.”
Why AI Labs Want DOE Sites
Frontier labs like OpenAI and Anthropic — and their cloud sponsors — need:
– Gigawatts of energy
– Secure compute environments
– Freedom from export rules and Freedom of Information Act requests
– Permitting shortcuts and national branding
The DOE sites offer all of that — plus built-in federal credibility. The same labs currently arguing in court that their training practices are “fair use” now claim they are defenders of democracy training AI on taxpayer-built land.
This Isn’t the Manhattan Project — It’s the Extraction Economy in a Lab Coat
The tech industry loves to invoke patriotism when it’s convenient — especially when demanding access to federal land, nuclear infrastructure, or diplomatic cover from the EU’s AI Act. But let’s be clear:
This isn’t the Manhattan Project. Or rather we should hope it isn’t because that one didn’t end well and still hasn’t.
It’s not public service.
It’s Big Tech lying about fair use, wrapped in an American flag — and for all we know, it might be the first time David Sacks ever saw one.
When companies like OpenAI and Microsoft claim they’re defending democracy while building proprietary systems on DOE nuclear land, we’re not just being gaslit — we’re being looted.
If the AI revolution is built on nationalizing risk and privatizing power, it’s time to ask whose country this still is — and who gets to turn off the lights.
When Viceroy David Sacks Writes the Tariffs: How One VC Could Weaponize U.S. Trade Against the EU
David Sacks is a “Special Government Employee”, Silicon Valley insider and a PayPal mafioso who has become one of the most influential “unofficial” architects of AI policy under the Trump administration. No confirmation hearings, no formal role—but direct access to power.
He:
– Hosts influential political podcasts with Musk and Thiel-aligned narratives.
– Coordinates behind closed doors with elite AI companies who are now PRC-style “national champions” (OpenAI, Anthropic, Palantir).
– Has reportedly played a central role in shaping the AI Executive Orders and industrial strategy driving billions in public infrastructure to favored firms.
Under 18 U.S.C. § 202(a), a Special Government Employee is:
- Temporarily retained to perform limited government functions,
- For no more than 130 days per year (which for Sacks ends either April 14 or May 30, 2025), unless reappointed in a different role,
- Typically serves in an advisory or consultative role, or
- Without holding actual decision-making or operational authority over federal programs or agencies.
SGEs are used to avoid conflict-of-interest entanglements for outside experts while still tapping their expertise for advisory purposes. They are not supposed to wield sweeping executive power or effectively run a government program. Yeah, right.
And like a good little Silicon Valley weasel, Sacks supposedly is alternating between his DC side hustle and his VC office to stay under 130 days. This is a dumbass reading of the statute which says “‘Special Government employee’ means… any officer or employee…retained, designated, appointed, or employed…to perform…temporary duties… for not more than 130 days during any period of 365 consecutive days.” That’s not the same as “worked” 130 days on the time card punch. But oh well.

David Sacks has already exceeded the legal boundaries of his appointment as a Special Government Employee (SGE) both in time served but also by directing the implementation of a sweeping, whole-of-government AI policy, including authoring executive orders, issuing binding directives to federal agencies, and coordinating interagency enforcement strategies—actions that plainly constitute executive authority reserved for duly appointed officers under the Appointments Clause. As an SGE, Sacks is authorized only to provide temporary, nonbinding advice, not to exercise operational control or policy-setting discretion across the federal government. Accordingly, any executive actions taken at his direction or based on his advisement are constitutionally infirm as the unlawful product of an individual acting without valid authority, and must be deemed void as “fruit of the poisonous tree.”
Of course, one of the states that the Trump AI Executive Orders will collide with almost immediately is the European Union and its EU AI Act. Were they 51st? No that’s Canada. 52nd? Ah, right that’s Greenland. Must be 53rd.
How Could David Sacks Weaponize Trade Policy to Help His Constituents in Silicon Valley?
Here’s the playbook:
Engineer Executive Orders
Through his demonstrated access to Trump and senior White House officials, Sacks could promote executive orders under the International Emergency Economic Powers Act (IEEPA) or Section 301 of the Trade Act, aimed at punishing countries (like EU members) for “unfair restrictions” on U.S. AI exports or operations.
Something like this: “The European Union’s AI Act constitutes a discriminatory and protectionist measure targeting American AI innovation, and materially threatens U.S. national security and technological leadership.” I got your moratorium right here.
Leverage the USTR as a Blunt Instrument
The Office of the U.S. Trade Representative (USTR) can initiate investigations under Section 301 without needing new laws. All it takes is political will—and a nudge from someone like Viceroy Sacks—to argue that the EU’s AI Act discriminates against U.S. firms. See Canada’s “Tech Tax”. Gee, I wonder if Viceroy Sacks had anything to do with that one.
Redefine “National Security”
Sacks and his allies can exploit the Trump administration’s loose definition of “national security” claiming that restricting U.S. AI firms in Europe endangers critical defense and intelligence capabilities.
Smear Campaigns and Influence Operations
Sacks could launch more public campaigns against the EU like his attacks on the AI diffusion rule. According to the BBC, “Mr. Sacks cited the alienation of allies as one of his key arguments against the AI diffusion plan”. That’s a nice ally you got there, be a shame if something happened to it.
After all, the EU AI Act does what Sacks despises like protects artists and consumers, restricts deployment of high-risk AI systems (like facial recognition and social scoring), requires documentation of training data (which exposes copyright violations), and applies extraterritorially (meaning U.S. firms must comply even at home).
And don’t forget, Viceroy Sacks actually was given a portfolio that at least indirectly includes the National Security Council, so he can use the NATO connection to put a fine edge on his “industrial patriotism” just as war looms over Europe.
When Policy Becomes Personal
In a healthy democracy, trade retaliation should be guided by evidence, public interest, and formal process.
But under the current setup, someone like David Sacks can short-circuit the system—turning a private grievance into a national trade war. He’s already done it to consumers, wrongful death claims and copyright, why not join war lords like Eric Schmidt and really jack with people? Like give deduplication a whole new meaning.
When one man’s ideology becomes national policy, it’s not just bad governance.
It’s a broligarchy in real time.
AI Needs Ever More Electricity—And Google Wants Us to Pay for It
Uncle Sugar’s “National Emergency” Pitch to Congress
At a recent Congressional hearing, former Google CEO Eric “Uncle Sugar” Schmidt delivered a message that was as jingoistic as it was revealing: if America wants to win the AI arms race, it better start building power plants. Fast. But the subtext was even clearer—he expects the taxpayer to foot the bill because, you know, the Chinese Communist Party. Yes, when it comes to fighting the Red Menace, the all-American boys in Silicon Valley will stand ready to fight to the last Ukrainian, or Taiwanese, or even Texan.
Testifying before the House Energy & Commerce Committee on April 9, Schmidt warned that AI’s natural limit isn’t chips—it’s electricity. He projected that the U.S. would need 92 gigawatts of new generation capacity—the equivalent of nearly 100 nuclear reactors—to keep up with AI demand.
Schmidt didn’t propose that Google, OpenAI, Meta, or Microsoft pay for this themselves, just like they didn’t pay for broadband penetration. No, Uncle Sugar pushed for permitting reform, federal subsidies, and government-driven buildouts of new energy infrastructure. In plain English? He wants the public sector to do the hard and expensive work of generating the electricity that Big Tech will profit from.
Will this Improve the Grid?
And let’s not forget: the U.S. electric grid is already dangerously fragile. It’s aging, fragmented, and increasingly vulnerable to cyberattacks, electromagnetic pulse (EMP) weapons, and even extreme weather events. Pouring public money into ultra-centralized AI data infrastructure—without first securing the grid itself—is like building a mansion on a cracked foundation.
If we are going to incur public debt, we should prioritize resilience, distributed energy, grid security, and community-level reliability—not a gold-plated private infrastructure buildout for companies that already have trillion-dollar valuations.
Big Tech’s Growing Appetite—and Private Hoarding
This isn’t just a future problem. The data center buildout is already in full swing and your Uncle Sugar must be getting nervous about where he’s going to get the money from to run his AI and his autonomous drone weapons. In Oregon, where electricity is famously cheap thanks to the Bonneville Power Administration’s hydroelectric dams on the Columbia River, tech companies have quietly snapped up huge portions of the grid’s output. What was once a shared public benefit—affordable, renewable power—is now being monopolized by AI compute farms whose profits leave the region to the bank accounts in Silicon Valley.
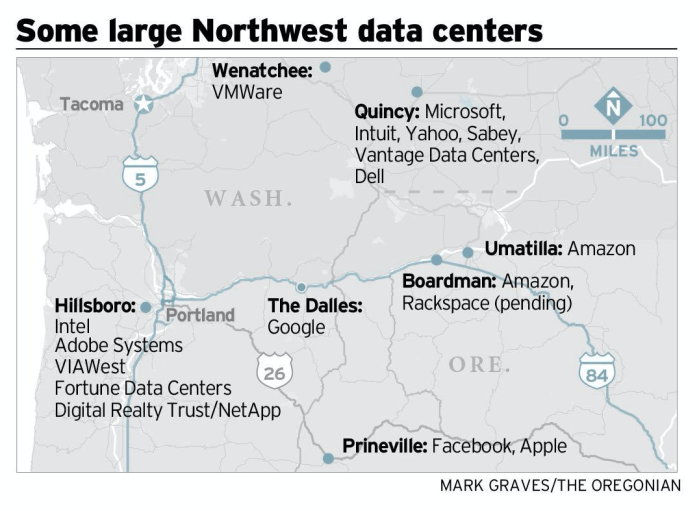
Meanwhile, Microsoft is investing in a nuclear-powered data center next to the defunct Three Mile Island reactor—but again, it’s not about public benefit. It’s about keeping Azure’s training workloads running 24/7. And don’t expect them to share any of that power capacity with the public—or even with neighboring hospitals, schools, or communities.
Letting the Public Build Private Fortresses
The real play here isn’t just to use public power—it’s to get the public to build the power infrastructure, and then seal it off for proprietary use. Moats work both ways.
That includes:
– Publicly funded transmission lines across hundreds of miles to deliver power to remote server farms;
– Publicly subsidized generation capacity (nuclear, gas, solar, hydro—you name it);
– And potentially, prioritized access to the grid that lets AI workloads run while the rest of us face rolling blackouts during heatwaves.
All while tech giants don’t share their models, don’t open their training data, and don’t make their outputs public goods. It’s a privatized extractive model, powered by your tax dollars.
Been Burning for Decades
Don’t forget: Google and YouTube have already been burning massive amounts of electricity for 20 years. It didn’t start with ChatGPT or Gemini. Serving billions of search queries, video streams, and cloud storage events every day requires a permanent baseload—yet somehow this sudden “AI emergency” is being treated like a surprise, as if nobody saw it coming.
If they knew this was coming (and they did), why didn’t they build the power? Why didn’t they plan for sustainability? Why is the public now being told it’s our job to fix their bottleneck?
The Cold War Analogy—Flipped on Its Head
Some industry advocates argue that breaking up Big Tech or slowing AI infrastructure would be like disarming during a new Cold War with China. But Gail Slater, the Assistant Attorney General leading the DOJ’s Antitrust Division, pushed back forcefully—not at a hearing, but on the War Room podcast.
In that interview, Slater recalled how AT&T tried to frame its 1980s breakup as a national security threat, arguing it would hurt America’s Cold War posture. But the DOJ did it anyway—and it led to an explosion of innovation in wireless technology.
“AT&T said, ‘You can’t do this. We are a national champion. We are critical to this country’s success. We will lose the Cold War if you break up AT&T,’ in so many words. … Even so, [the DOJ] moved forward … America didn’t lose the Cold War, and … from that breakup came a lot of competition and innovation.”
“I learned that in order to compete against China, we need to be in all these global races the American way. And what I mean by that is we’ll never beat China by becoming more like China. China has national champions, they have a controlled economy, et cetera, et cetera.
We win all these races and history has taught by our free market system, by letting the ball rip, by letting companies compete, by innovating one another. And the reason why antitrust matters to that picture, to the free market system is because we’re the cop on the beat at the end of the day. We step in when competition is not working and we ensure that markets remain competitive.”
Slater’s message was clear: regulation and competition enforcement are not threats to national strength—they’re prerequisites to it. So there’s no way that the richest corporations in commercial history should be subsidized by the American taxpayer.
Bottom Line: It’s Public Risk, Private Reward
Let’s be clear:
– They want the public to bear the cost of new electricity generation.
– They want the public to underwrite transmission lines.
– They want the public to streamline regulatory hurdles.
– And they plan to privatize the upside, lock down the infrastructure, keep their models secret and socialize the investment risk.
This isn’t a public-private partnership. It’s a one-way extraction scheme. America needs a serious conversation about energy—but it shouldn’t begin with asking taxpayers to bail out the richest companies in commercial history.
Does “Publicly Available” AI Scraping Mean They Take Everything or Just Anything That’s Not Nailed Down?
Let’s be clear: It is not artificial intelligence as a technology that’s the existential threat. It’s the people who make the decisions about how to train and use artificial intelligence that are the existential threat. Just like nuclear power is not an existential threat, it’s the Czar Bomba that measured 50 megatons on the bangometer that’s the existential threat.
If you think that the tech bros can be trusted not to use your data scraped from their various consumer products for their own training purposes, please point to the five things they’ve done in the last 20 years that give you that confidence? Or point to even one thing.
Here’s an example. Back in the day when we were trying to build a library of audio fingerprints, we first had to rip millions of tracks in order to create the fingerprints. One employee who came to us from a company with a free email service said that there were millions of emails with audio file attachments just sitting there in users’ sent mail folders. Maybe we could just grab those audio files? Obviously that would be off limits for a host of reasons, but he didn’t see it. It’s not that he is an immoral person–immoral people recognize that there are some rules and they just want to break them. He was amoral–he didn’t see the rules and he didn’t think anything was wrong with his suggestion.
But the moral of the story–so to speak–is that I fully believe every consumer product is being scraped. That means that there’s a fairly good chance that Google, Microsoft, Meta/Facebook and probably other Big Tech players are using all of their consumer products to train AI. I would not bet against it.
If you think that’s crazy, I would suggest you think again. While these companies keep that kind of thing fairly quiet, it’s not the first time that the issue has come up–Big Tech telling you one thing, but using you to gain a benefit for something entirely different that you probably would never have agreed to had you known.
Take the Google Books saga. The whole point of Google’s effort at digitizing all the world’s books wasn’t because of some do-gooder desire to create the digital library of Alexandria or even the snippets that were the heart of the case. No–it was the “nondisplay uses” like training Google’s translation engine using “corpus machine translation”. The “corpus” of all the digitized books was the real value and of course was the main thing that Google wouldn’t share with the authors and didn’t want to discuss in the case.
Another random example would be “GOOG-411”. We can thank Marissa Meyer for spilling the beans on that one.
According to PC World back in 2010:
Google will close down 1-800-GOOG-411 next month, saying the free directory assistance service has served its purpose in helping the company develop other, more sophisticated voice-powered technologies.
GOOG-411, which will be unplugged on Nov. 12, was the search company’s first speech recognition service and led to the development of mobile services like Voice Search, Voice Input and Voice Actions.
Google, which recorded calls made to GOOG-411, has been candid all along about the motivations behind running the service, which provides phone numbers for businesses in the U.S. and Canada.
In 2007, Google Vice President of Search Products & User Experience Marissa Mayer said she was skeptical that free directory assistance could be viable business, but that she had no doubt that GOOG-411 was key to the company’s efforts to build speech-to-text services.
GOOG 411 is a prime example of how Big Tech plays the thimblerig, especially the “has been candid all along about the motivations behind running the service.” Doesn’t that phrase just ooze corporate flak? That, as we say in the trade, is a freaking lie.

None of the GOOG-411 collateral ever said, “Hey idiot, come help us get even richer by using our dumbass “free” directory assistance “service”.” Just like they’re not saying, “Hey idiot, use our “free” products so we can train our AI to take your job.” That’s the thimblerig, but played at our expense.
This subterfuge has big consequences for people like lawyers. As I wrote in my 2014 piece in Texas Lawyer:
“A lawyer’s duty to maintain the confidentiality of privileged communications is axiomatic. Given Google’s scanning and data mining capabilities, can lawyers using Gmail comply with that duty without their clients’ informed consent? In addition to scanning the text, senders and recipients, Google’s patents for its Gmail applications claim very broad functionality to scan file attachments. (The main patent is available on Google’s site. A good discussion of these patents is in Jeff Gould’s article, “The Natural History of Gmail Data Mining”, available on Medium.)”
Google has made a science of enticing users into giving up free data for Google to evolve even more products that may or may not be useful beyond the “free” part. Does the world really need another free email program? Maybe not, but Google does need a way to snarf down data for its artificial intelligence platforms–deceptively.
Fast forward ten years or so and here we are with the same problem–except it’s entirely possible that all of the Big Tech AI platforms are using their consumer products to train AI. Nothing has changed for lawyers, and some version of these rules would be prudent to follow for anyone with a duty of confidentiality like a doctor, accountant, stock broker or any of the many licensed professions. Not to mention social workers, priests, and the list goes on. If you call Big Tech on the deception and they will all say that they operate within their privacy policies, “de-identify” user data, only use “public” information, or other excuses.
I think the point of all this is that the platforms have far too many opportunities to cross-collateralize our data for the law to permit any confusion about what data they scrape.
What We Think We Know
Microsoft’s AI Training Practices
Microsoft has publicly stated that it does not use data from its Microsoft 365 products (e.g., Word, Excel, Outlook) to train its AI models. The company wants us to believe they rely on “de-identified” data from sources such as Bing searches, Copilot interactions, and “publicly available” information, whatever that means. Microsoft emphasizes its commitment to responsible AI practices, including removing metadata and anonymizing data to protect user privacy. See what I mean? Given Microsoft takes these precautions, that makes it all fine.
However, professionals using Microsoft’s tools must remain vigilant. While Microsoft claims not to use customer data from enterprise accounts for AI training, any inadvertent sharing of sensitive information through other Microsoft services (e.g., Bing or Copilot) could pose risks for users, particularly people with a duty of confidentiality like lawyers and doctors. And we haven’t even discussed child users yet.
Google’s AI Training Practices
For decades, Google has faced scrutiny for its data practices, particularly with products like Gmail, Google Docs, and Google Drive. Google’s updated privacy policy explicitly allows the use of “publicly available” information and user data for training its AI models, including Bard and Gemini. While Google claims to anonymize and de-identify data, concerns remain about the potential for sensitive information to be inadvertently included in training datasets.
For licensed professionals, these practices raise significant red flags. Google advises users not to input confidential or sensitive information into its AI-powered tools–typically Googlely. The risk of human reviewers accessing “de-identified” data can happen to anyone, but why in the world would you ever trust Google?
Does “Publicly Available” Mean Everything or Does it Mean Anything That’s Not Nailed Down?
These companies speak of “publicly available” data as if data that is publicly available is free to scrape and use for training. So what does that mean?
Based on the context and some poking around, it appears that there is no legally recognizable definition of what “publicly available” actually means. If you were going to draw a line between “publicly available” and the opposite, where would you draw it? You won’t be surprised to know that Big Tech will probably draw the line in an entirely different place than a normal person.
As far as I can tell, “publicly available” data would include data or content that is accessible by a data scraping crawler or by the general public without a subscription, payment, or special access permissions. This likely includes web pages, posts on social media like baby pictures on Facebook or Instagram, or other platforms that do not restrict access to their content through paywalls, registration requirements, or other barriers like terms of service prohibiting data scraping, API or a robots.txt file (which like a lot of other people including Ed Newton-Rex, I’m skeptical of even working).
While discussions of terms of service, notices prohibiting scraping and automated directions to crawlers sound good, in reality there’s no way to stop a determined crawler. The vulpine lust for data and cold hard cash by Big Tech is not realistically possible to stop at this point. Stopping the existential onslaught explains why the world needs to escalate punishment for these violations to a new level that may seem extreme at this point or at least unusually harsh.
Yet the massive and intentional copyright infringement, privacy violations, and who knows what else are so vast they are beyond civil penalties particularly for a defendant that seemingly prints money.
If You Don’t Vote…
WILLIE
If you don’t vote, you don’t matter…you don’t matter…you don’t matter. And then you’s just as ignorant as them in the city say you is while they stealing the food off your table and every last nickel out your pocket saying thank you please. ‘Cuz then you are just a bunch of ignorant hicks who got nothing because you deserve nothing.
All the King’s Men, Screenplay by Steven Zaillian, based on the novel by Robert Penn Warren (2006 version) with one of the best James Horner scores by that fellow Bruin.

