The most important data center story today wasn’t a zoning hearing, a transmission line fight, or a new hyperscaler valuation announcement.
The most important story is a poll. And that poll may not only capture the sentiment of the public, it may also indicate which way elected officials and financiers are leaning, too.

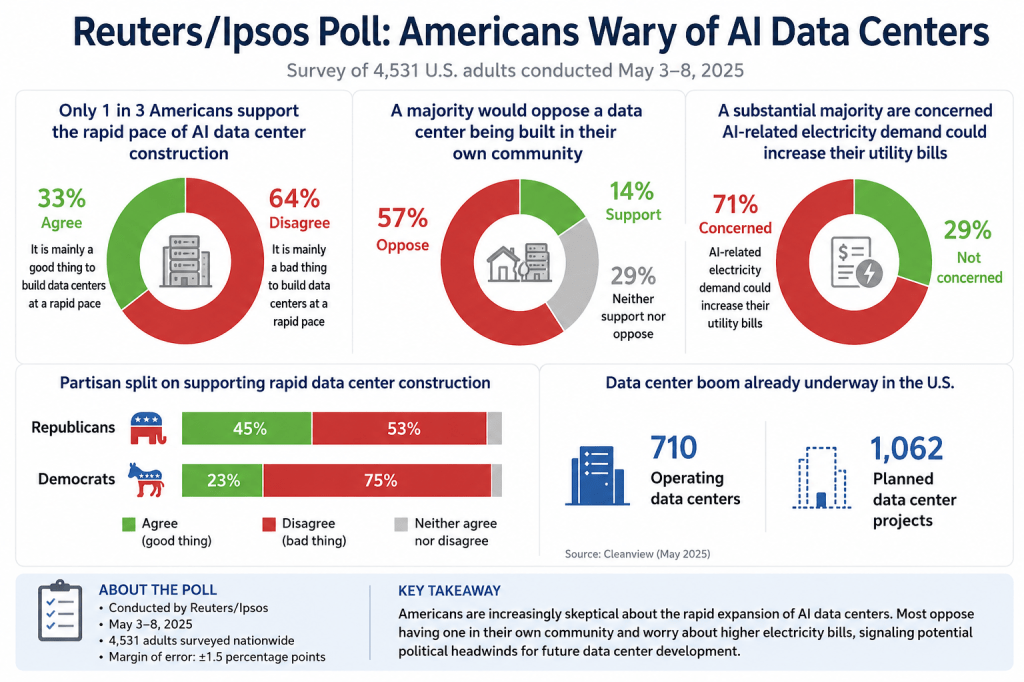
A new Reuters/Ipsos survey found that only one-third of Americans support the current pace of AI data center construction, while nearly two-thirds oppose it. More than half said they would oppose a data center in their own community, and a substantial majority expressed concern that AI-related electricity demand could increase their utility bills.
The six-day poll, which surveyed 4,531 people across the country and closed on Monday, showed just 33% of Americans agreed with a statement that it was mainly a good thing to build data centers at a rapid pace. Some 64% disagreed….Some 57% of people surveyed – including two-thirds of Democrats and half of Republicans – also said they would oppose a data center being built in their community. Just 14% of survey takers said they were okay with a center being built near them, according to the Reuters/Ipsos poll.
The lopsided result should not be surprising.
For the past two years, the public conversation around data centers has focused on American AI leadership (“because China”), economic development, and technological competitiveness. But many communities are experiencing something very different: transmission line easements criss-crossing private property, industrial-scale facilities near homes, rising utility concerns, water consumption, noise, and tax incentives for some of the world’s largest companies. It may be starting to dawn on the public why the White House AI Czar David Sacks was so obsessed with blocking any state laws that got in the way of AI.

In some cases, the issue goes even further. Landowners are being asked to surrender property rights through eminent domain—or the threat of eminent domain—so that transmission infrastructure can be built to serve facilities whose ultimate beneficiaries are among the wealthiest technology companies in the world.
Imagine you were the man who fell to earth and you knew nothing about AI workflow. Would you look at all these data centers, substations, behind the meter nuclear reactors and transmission lines and say “oh, that makes total sense”? Or would you ask what are these people thinking building a supply chain this kludgy with myriad points of failure? Data centers in space? Really? What could possibly go wrong?

That is where the national security narrative begins to collide with local reality. “We have to do this because China” is a powerful slogan in Washington. For many landowners outside the Imperial City, however, it begins to ring hollow when the immediate consequence is a transmission easement across family property that will never happen in an urban setting.
This is particularly true when the economic justification depends on AI demand forecasts that may not even be tested—much less achieved—for years. Viewed from a kitchen window looking out at a new transmission corridor in what used to be your vegetable garden or a pasture for livestock, the sacrifice is immediate and personal, while the promised strategic benefits remain abstract and distant.
We’ve already seen an econometric study from Professor Michael Hicks at Ball State University showing that all the hundreds of data centers in Texas have led to pretty much a wash in job creation, a major selling point that few ever believed. A University of Texas study shows that data centers could potentially account for 3% to 9% of Texas’ water use by 2040, according to a new white paper. In other words, Big Data has largely been talking about the benefits of AI while residents have been living with the costs of that infrastructure.


The Reuters/Ipsos poll suggests the issue may be evolving from a collection of local land-use disputes into a national political movement. Historically, that is the point where elected officials begin to change their behavior. Local opposition can often be dismissed as isolated resistance. National polling is harder to ignore and could be the harbinger of somebody getting unelected.
The challenge for policymakers, utilities, and developers is that public concerns are becoming increasingly tangible while many projected benefits remain tied to forecasts extending years into the future with no current evidence. Voters tend to react more strongly to immediate and permanent impacts than to promised future gains that may never come to pass, particularly gains to other people who don’t have a transmission line in their garden or who were not forced to sell their family home to a power company.
That leads to a data center mobilization question that has received far less attention than corrupting farm land, water use, noise, or electricity rates: what happens if the forecasts are simply wrong?

Communities are being asked to accept transmission corridors, substations, power plants, and massive industrial facilities today based on projections of future AI demand that may extend a decade or more into the future. Yet the economics of AI remain highly uncertain as this week’s Google $85 billion equity round confirms. When Google’s AI capital expenditures exceeded even Google’s free cash flow, the Leviathan of Mountain View turned to a Silicon Valley favorite: Other people’s money. Revenue models are still evolving, competition is intense, and many of the assumptions underlying today’s infrastructure buildout have not yet been tested through a full business cycle.
Crucially, Investors are funding unprecedented AI capex on the assumption of durable competitive advantages, yet the underlying LLM asset increasingly exhibits commodity characteristics. Meaning the models are all very similar in the fundamental components. As hyperscalers converge on functionally similar models, infrastructure, and services at extraordinary cost, there is less and less that distinguishes one from the other. When Google chooses to finance capex out of equity rather than continue financing from free cash flow and debt, that may also tell us something about the appetite of lenders getting a little skeptical.
It’s not just Google. Consider the implications of the recent reports surrounding SoftBank’s OpenAI investment. SoftBank participated in OpenAI’s February 2026 funding round at a valuation of approximately $840 billion and emerged with roughly 13% ownership. On paper, SoftBank’s stake in OpenAI carried an implied value of approximately $109 billion.
Yet when SoftBank reportedly sought to get a margin loan on those same shares a few weeks ago (three months after the $840 billion valuation was set) using that position as collateral, lenders appear to have viewed the value of the OpenAI shares very differently. The company initially sought a $10 billion loan secured by its OpenAI shares, later reducing the request to approximately $6 billion after lender interest reportedly proved limited. Even at the lower amount, loan negotiations have reportedly stalled.

The significance is not just that SoftBank’s OpenAI position is worth only $6 billion (implied $46B valuation) or $10 billion as margin loan collateral, if that. Rather, it highlights the distinction between venture valuation, financing valuation, and realizable value. An $840 billion venture valuation reflects what investors were willing to pay in a private financing round under specific assumptions about future growth, profitability, and market structure.
A margin lender asks a different question: if the collateral must be liquidated under adverse circumstances like a bubble burst or the recent semiconductor crash, what is it actually worth? The resulting margin discount can be substantial, even taking into account the usual 50%-ish haircut on marginable securities. For AI investors, this episode may be one of the first visible indications that sophisticated credit markets are assigning materially different risk assessments to AI assets than those implied by headline-grabbing private-market valuations fueled by cheerleading from the financial press and, it must be said, the Oval Office.
Similar valuation disconnects have appeared before other major public offerings, including Spotify’s direct listing, WeWork’s failed IPO, and several high-profile technology listings where private-market expectations ultimately confronted public-market price discovery. For AI investors, the significance is less about OpenAI itself than what the episode may reveal about the difference between AI forecasts and the willingness of sophisticated creditors to finance those assumptions with actual cash.
If those forecasts prove overly optimistic, the result may not simply be disappointed investors. The result could be stranded assets: transmission lines cutting across ranches and farms, substations occupying valuable land, and industrial facilities looming over communities long after the expected economic justification has faded. That burden may ultimately become the defining political challenge of the AI infrastructure era. People are not merely being asked to tolerate temporary construction. They are being asked to accept permanent changes both to their homes, to their property ownership, and to their communities in support of forecasts that may or may not materialize. If a ranch is involuntarily divided, a neighborhood industrialized, or a home taken for infrastructure justified by projected future AI demand, the consequences are real regardless of whether the forecast is ultimately correct.
The Reuters/Ipsos poll suggests that the next phase of the debate may be less about artificial intelligence itself and more about who bears the risks, costs, and consequences of the infrastructure being built to support it—and who bears the consequences for an unpopular mobilization if those forecasts turn out to be wrong.
That conversation—and the inevitable litigation—is only beginning.
