The current narrative says the “AI subsidy era” is ending. Prices are rising. Rate limits are tightening. Ads are creeping in. Enterprise tiers are replacing all-you-can-eat plans. In short: users will finally start paying what AI actually costs.
Earlier this month, millions of OpenClaw users woke up to a sweeping mandate: The viral AI agent tool, which this year took the worldwide tech industry by storm, had been severely restricted by Anthropic.
Anthropic, like other leading AI labs, was under immense pressure to lessen the strain on its systems and start turning a profit. So if the users wanted its Claude AI to power their popular agents, they’d have to start paying handsomely for the privilege.
“Our subscriptions weren’t built for the usage patterns of these third-party tools,” wrote Boris Cherny, head of Claude Code, on X. “We want to be intentional in managing our growth to continue to serve our customers sustainably long-term. This change is a step toward that.”
The announcement was a sign of the times. Investors have poured hundreds of billions of dollars into companies like OpenAI and Anthropic to help them scale and build out their compute. Now, they’re expecting returns. After years of offering cheap or totally free access to advanced AI systems, the bill is starting to come due — and downstream, users are beginning to feel the pinch.
That’s true but it’s leaving out a lot.
Yes, the consumer subsidy—venture-backed underpricing of inference—may be winding down. But the broader subsidy system that made AI possible isn’t going away. It’s expanding. Just ask President Trump.
To understand why, you have to go back to the last great digital disruption.
From P2P to Streaming to AI
Start with Napster.
P2P didn’t just enable infringement. It rewired expectations. It taught users that all music should be available, instantly, for free. Why? Because there was gold in them long tails. Forget about supply and demand, we had infinite supply so demand would take care of itself.
It’s for sale
Every artist, songwriter, label and publisher in the history of recorded music were not compensated for this shift. They were its involuntary financiers. Their catalogs created the demand, the network effects, and the user adoption that built the early internet music economy.
Streaming—think Spotify—didn’t reverse that logic. It formalized it. (Remember, streaming saved us from piracy and we should all be so grateful.) It actually transferred that involuntary financing from the p2p balance sheet to Spotify’s, and took it public.
Streaming platforms accepted a new baseline: the entire world’s repertoire must be available at all times, regardless of demand. That is a costly and structurally inefficient mandate, but it became the price of competing in a market shaped by P2P expectations. Licensing systems like the Mechanical Licensing Collective (MLC) were built to support that scale, but the underlying premise remained: total availability first, compensation second.
AI changes the game again.
AI Doesn’t Just Distribute Works. It Consumes Them.
P2P distributed music. Streaming licensed it. AI models ingest it.
That’s the critical difference.
Generative AI systems are trained on massive corpora that include copyrighted works, performances, and what we might call personhood signals—voice, style, tone, phrasing, and creative identity. These inputs are not just indexed or streamed. They are transmogrified (see what I did there) into model weights that can generate new outputs that compete with, mimic, or substitute for the originals.
So the role of the artist evolves: • In P2P: unpaid distributor subsidy • In streaming: underpaid inventory supplier • In AI: uncompensated production input That is not a marginal shift. It is a structural one.
The Real Subsidy Stack
When people say the “AI subsidy era is over,” they are usually talking about one thing: cheap access to compute. But AI has always depended on a multi-layered subsidy stack:
Creators – supply training data, cultural value, and identity signals without compensation or consent Users – supply prompts, feedback, and behavioral data that improve the models Communities – absorb land use, water consumption, and environmental costs Ratepayers – fund grid upgrades, transmission, and reliability for data center demand Venture capital – underwrites early losses to drive adoption and scale
The shift we are seeing now is not the end of subsidies. It’s a reallocation. Or as a cynic might say, it’s rearranging the deck chairs to hide the lifeboats.
Users may start paying more. But creators still aren’t being paid for training. Communities are still being asked to host infrastructure. And the physical footprint of AI is accelerating. Just ask President Trump.
The World Turned Upside Down
What makes this moment different is the scale of the buildout. We are not just talking about apps anymore. We are talking about an industrial transformation: • New data centers the size of small cities • High-voltage transmission lines • Water-intensive cooling systems • Semiconductor supply chains • And even discussions of new nuclear capacity to support compute demand
This is infrastructure on the scale of a national project, or more like national mobilization. But it is being built on top of a premise that has not been resolved: the uncompensated use of human creative work as training input.
That is the inversion: We are building power plants for systems that depend on not paying the people whose work makes those systems possible.
A Better Frame
The cleanest way to understand this is as a continuum:
P2P turned infringement into consumer expectation. Streaming turned that expectation into platform infrastructure. AI turns uncompensated authorship into industrial feedstock.
Or more bluntly: The AI free ride is not ending. It is being re-invoiced. Users may now see higher prices. But the deeper subsidies—creative, environmental, and civic—remain off the books.
What Comes Next
If the industry is serious about “pricing AI correctly,” it cannot stop at compute.
It has to address: • Compensation frameworks for training data • Attribution and provenance standards • Licensing models for style and voice • Infrastructure cost allocation (who pays for the grid?) • Governance of large-scale compute deployment
Otherwise, we are not exiting the subsidy era. We are doing what Big Tech lives for.
We are scaling it.
And this time, instead of a few server racks in a dorm room, we are building an global energy system around it.
In ancient Rome, Marcus Licinius Crassus was the wealthiest man alive. And he had a system. He owned real estate and he also owned the fire brigades. When a house caught fire, Crassus sent his men to the scene. But they didn’t rush in with water.
First, he made the owner an offer. Sell me your house for pennies. The house that is literally on fire. Agree to the price, and the fire would be put out. Refuse… and his fire brigade would simply watch it burn.
Some even whispered that Crassus’s men set fires themselves, just to create new ‘opportunities.’ Ya think?
It was ruthless. Ingenious. And it gave him his own kind of safe harbor. If you controlled the fire brigade… there was no liability. No regulator. No competition. Just profit. Because Crassus set the valuation.
Now—fast forward two thousand years. AI hyperscalers haven’t just rediscovered Crassus’s model. They’ve reimagined it.
The Valuation is the Thing
There is a moment in every cycle when the story stops even pretending to line up with the business. That moment usually shows up quietly at first, almost as a joke, and then all at once everyone realizes the joke is being taken seriously.
We may be there again.
Allbirds, a company that built its brand selling wool sneakers to a very specific kind of customer, is now pivoting into AI compute infrastructure. Not adjacent. Not evolutionary. Just a clean jump into GPUs and datacenters. The rebrand writes itself. NewBird AI.
If that sounds absurd, it should. But it should also feel familiar. The mistake is to focus on the technology. The technology is always real. The internet was real. AI is real. The mistake is to assume the valuation attached to that technology has anything to do with the underlying business. That part is almost always where things go sideways. The people. The ones who set the fires.
Fire Good, Valuations Bad
Look at the comps. Spotify sits around a one hundred billion dollar market cap. Universal Music Group is closer to thirty eight. Warner Music Group is around fifteen. The companies that own the music, the actual asset, the thing that endures, are worth a fraction of the company that packages and distributes it and will one day be replaced, just like streaming replaced CDs.
That is not a story about innovation. It is a story about what the market chooses to value.
Once you see that, the Allbirds pivot stops looking irrational. It starts looking like one of the only logical moves available. If the market assigns higher multiples to infrastructure, to platforms, to anything that can be described as scalable, then the rational response is to become that thing. Not because the company has any particular advantage in doing so, but because the category itself carries the valuation.
We have seen this movie before. In the late nineties, companies selling ordinary products wrapped themselves in the language of the internet. They were not retailers. They were platforms. They were not losing money. Oh no, no, no. They were scaling. They could IPO with four quarters of top line revenue. The technology stack became the story. The story became the valuation. The underlying business became almost incidental. Larry Ellison’s famous spoof Internet company, HeyIdiot.com was a “cash portal” that only sold one product, being shares of HeyIdiot.com stock at incrementally higher prices to even greater fools.
The systems built around those businesses grew increasingly complex. Layers of software justified layers of capital. At the same time, the basic economics often made less and less sense. Somewhere outside the pitch decks, the vulnerabilities were obvious. The infrastructure was fragile. The incentives were misaligned. But the narrative carried everything forward until it didn’t.
This cycle has its own vocabulary. Instead of platforms and portals, we have models and compute. Instead of e commerce infrastructure, we have GPU clusters. The words are different. The behavior is not.
But somebody’s AI is not in on the joke…
“Part of their exploration into new ideas within the tech industry?” Say what? Somebody’s not in on the joke.
The pattern is simple. Take something real and wrap it in something that can be described as infinite, like you know, shelf space for the long tail. The wrapper gets the multiple. The underlying asset becomes an input cost. Over time, the market forgets the difference. Particularly with help from Mary Meeker.
That is how you end up with a distributor valued above the content it distributes. It is how you end up with a sneaker company presenting itself as a datacenter operator. It is how each cycle convinces itself that it has broken from the last one when it is mostly repeating it with better branding.
Same popcorn. Different wrapper.
None of this requires believing that AI is not important. It is. None of this requires believing that compute does not matter. It does. The question is not whether the technology is real. The question is why the valuation attached to it keeps drifting so far from the businesses claiming it.
There is a point where companies stop explaining how they make money and start explaining what category they belong to. That is usually the point where the market has shifted from pricing businesses to pricing narratives.
When that happens, the incentives become clear. You do not need to build the best company. You need to be seen as the right kind of company. You need the HeyIdiot wrapper.
So no, this is not about the macro environment. It is not about timing the cycle or reading the tea leaves of innovation.
It is simpler than that.
It is the valuation, stupid.
And yes, it is still stupid. But as Crassus might tell you, the house is also still on fire, mofo. What do you want to do about it?
As generative music systems like Suno and Udio move into the center of copyright debates, one question keeps coming up: Can we actually tell which songs influenced an AI-generated track? And then can we use that determination in a host of other processes like royalty payments?
Recently a number of people have pointed to research from Sony AI as evidence that the answer might be yes. Sony has publicly discussed work on tools designed to analyze the relationship between training data and AI-generated music outputs.
But the reality is a little more nuanced. Sony’s work is interesting and potentially important—but it is often misunderstood. What Sony has described is not a magic detector that can listen to a generated song and instantly reveal every recording the model trained on.
Instead, Sony is describing something more modest—and in some ways more useful.
Let’s unpack what the technology appears to do right now.
The first is training-data attribution. This means trying to estimate which recordings in a model’s training dataset influenced a generated output.
The second is musical similarity or version matching. This involves detecting when two pieces of music share meaningful musical material even if they are not exact copies of each other.
Sony has framed both efforts as research directions rather than a finished commercial product. In other words, this is still a developing technical approach, not a turnkey system that can produce definitive copyright answers.
That title sounds intimidating, but the basic idea is fairly intuitive and also suggests the project is part of the broader machine unlearning academic discipline.
The system does not operate like Shazam. It does not simply listen to an AI-generated song and say:
“This track was trained on Song X, Song Y, and Song Z.”
Instead, the approach works more like this.
Imagine you already know—or at least suspect—which recordings were used to train the model. You have a candidate set of training tracks.
The system then asks:
Among these training recordings, which ones seem most likely to have influenced this generated output?
In other words, the system ranks influence among known candidates.
The research approach borrows from an area of machine learning called machine unlearning, which studies how particular training examples affect a model’s behavior. In simplified terms, researchers can test how the model behaves when certain training examples are removed or adjusted. If the output changes meaningfully, that suggests those examples had measurable influence.
The important point is that this is an influence-ranking tool, not a forensic detector.
It tries to answer:
“Which of these known training tracks mattered most?”
Not:
“Tell me every song the model was trained on.”
Sony’s Other Idea: Smarter Music Comparison
Sony has also described work on musical similarity detection.
Traditional audio fingerprinting systems—like those used by Shazam or Audible Magic—are very good at identifying identical recordings. If you upload the same song or a slightly altered version, the system can match it.
But generative AI raises a different problem. An AI output might resemble a song musically without copying the recording itself.
Sony’s research tries to detect those kinds of relationships.
For example, a system might notice that two tracks share melodic fragments, rhythmic patterns, harmonic progressions, or musical phrases even if the arrangement, production, or instrumentation is different.
In plain English, this kind of tool tries to answer a different question:
“Are these two pieces of music related in substance?”
Not:
“Are they the exact same recording?”
The Big Limitation: You Still Need the Training Dataset
Here’s the key limitation that often gets overlooked.
Sony’s attribution approach appears to depend on having access to the candidate training dataset.
The system works by comparing a generated output against recordings that are already known or suspected to have been used during training. It estimates influence among those candidates.
That means the system answers the question:
“Which of these training tracks influenced the output?”
But it does not answer the question:
“What unknown recordings were used to train this model?”
If the training corpus is hidden or undisclosed, the attribution system has nothing to test against.
This makes the technology conceptually similar to many machine-learning research experiments, which measure influence using known datasets. Researchers can test influence among known training examples, but they cannot reconstruct an unknown dataset from outputs alone.
What This Could Look Like in the Real World
If the training corpus were known, a practical workflow might look like this.
First, the recordings in the training corpus would be identified. Audio fingerprinting systems could match those recordings to commercial releases.
That step answers the question:
What copyrighted recordings appear in the training data?
Then an attribution tool like the one Sony describes could be used to analyze generated outputs and estimate which of those known recordings appear to have influenced them.
This would not prove copying in every case. But it could dramatically narrow the analysis—from millions of possible influences to a smaller list of likely candidates.
What Sony Has Not Claimed
Sony’s public statements do not suggest that the attribution problem is solved.
Sony has not announced a system that automatically calculates track-by-track royalty payments for AI-generated songs. Nor has it described a tool that conclusively proves copyright copying from an AI output alone.
Instead, the work is framed as research aimed at improving transparency and accountability in generative music systems.
Why Labels Might Still Be Interested
Even with these limitations, the idea could be attractive to rights holders.
If training datasets were known, attribution tools could theoretically support new ways of analyzing how music catalogs interact with generative AI systems.
For example, such tools might help support:
royalty allocation models
influence-weighted compensation frameworks
catalog analytics
AI audit trails showing how repertoire contributes to model behavior
In other words, the technology could potentially become a measurement tool for how music catalogs influence generative systems.
What Sony did and did not do (yet)
Sony’s work does not magically reveal every song an AI model trained on. And it does not eliminate the need to know what is in the training dataset.
Instead, its value appears to lie after the training data is known.
Once you have a candidate training corpus, tools like the ones Sony describes may help analyze which recordings influenced particular outputs.
That makes the technology best understood as a post-disclosure attribution layer, not a substitute for knowing what recordings were used in training in the first place.
When the TikTok USDS deal was announced under the Protecting Americans from Foreign Adversary Controlled Applications Act, it was framed as a clean resolution to years of national-security concerns expressed by many in the US. TikTok was to be reborn as a U.S. company, with U.S. control, and foreign influence neutralized. But if you look past the press language and focus on incentives, ownership, and law, a different picture emerges.
TikTok’s “forced sale” under the PAFACA (not to be confused with COVFEFE) traces back to years of U.S. national-security concern that TikTok’s owner ByteDance—one of the People’s Republic of China’s biggest tech companies founded by Zhang Yiming among China’s richest men and a self-described member of the ruling Chinese Communist Party—could be compelled under PRC law to share data or to allow the CCP to influence the platform’s operations. TikTok and its lobbyists repeatedly attempted to deflect the attention of regulators through measures like U.S. data localization and third-party oversight (e.g., “Project Texas”). However, lawmakers concluded that aggressive structural separation—not promises which nobody was buying—was needed. Congress then passed, and President Biden signed, legislation requiring either divestiture of “foreign adversary controlled” apps like TikTok or face a total a U.S. ban. Facing app-store and infrastructure cutoff risk, TikTok and ByteDance pursued a restructuring to keep U.S. operations alive and maintain an exit to US financial markets.
Lawmakers’ concerns were real and obvious. By trading on social media addiction, TikTok can compile rich behavioral profiles—especially on minors—by combining what users watch, like, share, search, linger on, and who they interact with, along with device identifiers, network data, and (where permitted) location signals. At scale, that kind of telemetry can be used to infer vulnerabilities and target susceptibility. For the military, the concern is not only “TikTok tracks troop movements,” but also that social media posts, aggregated location and social-graph signals across hundreds of millions of users could reveal patterns around bases, deployments, routines, or sensitive communities—hence warnings that harvested information could “possibly even reveal troop movements,” hence TikTok’s longstanding bans on government-issued devices.
These concerns shot through government circles while the Tok became ubiquitous and carefully engineered social media addiction gripped the US, and indeed the West. (TikTok just this week settled out of the biggest social media litigation in history.) Congress was very concerned and with good reason—Rep. Mike Gallagher demanded that TikTok “Break up with the Chinese Communist Party (CCP) or lose access to your American users.” Rep. Cathy McMorris Rodgers said the bill would “prevent foreign adversaries, such as China, from surveilling and manipulating the American people.” Sen. Pete Ricketts warned “If the Chinese Communist Party is refusing to let ByteDance sell TikTok… they don’t want [control of] those algorithms coming to America.”
And of course, who can forget a classic Marsha line from Senator Marsha Blackburn. I don’t know how to say “Bless your heart” in Mandarin, but in English it’s “we heard you were opening a TikTok headquarters in Nashville and what you’re probably going to find is that the welcome mat isn’t going to be rolled out for you in Nashville.”
So there’s that.
TikTok can compile rich behavioral profiles—especially on minors—by combining what users post, watch, like, share, search, linger on, and who they interact with, along with device identifiers, network data, and location signals. At scale, that kind of telemetry can be used to infer vulnerabilities and targeting susceptibility. These exploits have real strategic value. With the CCP’s interest in undermining US interests and especially blunting the military, the concern is not necessarily that “the CCP tracks troop movements” directly (although who really knows), but that aggregated location and social-graph signals could reveal patterns around bases, deployments, routines, or sensitive communities—hence warnings that harvested information could “possibly even reveal troop movements,” and the TikTok’s longstanding bans on government-issued devices. You know, kind of like if you flew a balloon across the CONUS. military bases.
It must also be said that when you watch TikTok’s poor performance before Congress at hearings, it really came down to a simple question of trust. I think nobody believed a word they said and the TikTok witnesses exuded a kind of arrogance that simply does not work when Congress has a bit in the teeth. Full disclosure, I have never believed a word they said and have always been troubled that artists were unwittingly leading their fans to the social media abattoir.
I’ve been writing about TikTok for years, and not because it was fashionable or politically easy. After a classic MTP-style presentation at the MusicBiz conference in 2020 where I laid out all the issues with TikTok and the CCP, somehow I never got invited back. Back in 2020, I warned that “you don’t need proof of misuse to have a national security problem—you only need legal leverage and opacity.” I also argued that “data localization doesn’t solve a governance problem when the parent company [Bytedance] remains subject to foreign national security law,” and that focusing on the location of data storage missed “the more important question of who controls the system that decides what people see.” The forced sale didn’t vindicate any one prediction so much as confirm the basic point: structure matters more than assurances, and control matters more than rhetoric. I still have that concern after all the sound and fury.
There is also a legitimate constitutional concern with PAFACA: a government-mandated divestiture risks resembling a Fifth Amendment taking if structured to coerce a sale without just compensation. PAFACA deserved serious scrutiny even given the legitimate national security concerns. Had the dust settled with the CCP suing the U.S. government under a takings theory, it would have been both too cute by half and entirely on-brand—an example of the CCP’s “unrestricted warfare” approach to lawfare, exploiting Western legal norms strategically. (The CCP’s leading military strategy doctrine, Unrestricted Warfare poses terrorism (and “terror-like” economic and information attacks such as TikTok’s potential use) as part of a spectrum of asymmetric methods that can weaken a technologically superior power like the US.)
Indeed, TikTok did challenge the divest-or-ban statute in the Supreme Court and mounted a SOPA-style campaign that largely failed. TikTok argued that a government-mandated forced sale violated the First Amendment rights of its users and exceeded Congress’s national-security authority. The Supreme Court upheld (unanimously) the PAFACA law, concluding that Congress permissibly targeted foreign-adversary control for national-security reasons rather than suppressing speech, and that the resulting burden on expression did not violate the First Amendment. The case ultimately underscored how far national-security rationales can narrow judicial appetite to second-guess political branches in foreign-adversary disputes no matter how many high-priced lawyers, lobbyists and spin doctors line up at your table. And, boy, did they have them. I think at one point close to half the shilleries in DC were on the PRC payroll.
In that sense, the TikTok deal itself may prove to be another illustration of Master Sun’s maxim about winning without fighting, i.e., achieving strategic advantage not through open confrontation, but by shaping the terrain, the rules, and the opponent’s choices in advance—and perhaps most importantly in this case…deception.
But the deal we got is the deal we have so let’s see what we actually have achieved (or how bad we got hosed this time). As I often say, it’s a damn good thing we never let another MTV build a business on our backs.
The Three Pillars of TikTok
TikTok USDS is the U.S.-domiciled parent holding company for TikTok’s American operations, created to comply with the divest-or-ban law. It is majority owned by U.S. investors, with ByteDance retaining a non-controlling minority stake (reported around 19.9%) and licensing core recommendation technology to the U.S. business. (Under U.S. GAAP, 20%+ ownership is a common rebuttable presumption of “significant influence,” which can trigger less favorable accounting and more scrutiny of the relationship. Staying below 20% helps keep the stake looking purely passive which is kind of a joke considering Byte still owns the key asset. And we still have to ask if BD (or CCP) has any special voting rights (“golden share”), board control, dual-class stock, etc.)
The deal appears to rest on three pillars—and taken together, they point to something closer to an ouroboros than a divestment: the structure consumes itself, leaving ByteDance, and by extension the PRC, in a position that is materially different on paper but strikingly similar in practice.
Pillar One: ByteDance Keeps the Crown Jewel
The first and most important point is the simplest: ByteDance retains ownership of TikTok’s recommendation algorithm.
That algorithm is not an ancillary asset. It is TikTok’s product. Engagement, ad pricing, cultural reach, and political concern all flow from it. Selling TikTok without selling the algorithm is like selling a car without the engine and calling it a divestiture because the buyer controls the steering wheel.
Public reporting strongly suggests the solution was not a sale of the algorithm, but a license or controlled use arrangement. TikTok USDS may own U.S.-specific “tweaks”—content moderation parameters, weighting adjustments, compliance filters—but those sit on top of a core system ByteDance still owns and controls.
That distinction matters, because ownership determines who ultimately controls:
architectural changes,
major updates,
retraining methodology,
and long-term evolution of the system.
In other words, the cap table changed, but the switch did not necessarily move.
Pillar Two: IPO Optionality Without Immediate Disclosure
The second pillar is liquidity. ByteDance did not fight this battle simply to keep operating TikTok in the U.S.; it fought to preserve access to an exit in US financial markets.
The TikTok USDS structure clearly keeps open a path to an eventual IPO. Waiting a year or two is not a downside. There is a crowded IPO pipeline already—AI platforms, infrastructure plays, defense-adjacent tech—and time helps normalize the structure politically and operationally.
But here’s the catch: an IPO collapses ambiguity.
A public S-1 would have to disclose, in plain English:
who owns the algorithm,
whether TikTok USDS owns it or licenses it,
the material terms of any license,
and the risks associated with dependence on a foreign related party.
This is where old Obama-era China-listing tricks no longer work. Based on what I’ve read, TikTok USDS would likely be a U.S. issuer with a U.S.-inspectable auditor. ByteDance can’t lean on the old HFCAA/PCAOB opacity playbook, because HFCAA is about audit access—not about shielding a related-party licensor from scrutiny.
ByteDance surely knows this. Which is why the structure buys time, not relief from transparency. The IPO is possible—but only when the market is ready to price the risk that the politics are currently papering over.
Pillar Three: PRC Law as the Ultimate Escape Hatch
The third pillar is the quiet one, but it may be the most consequential: PRC law as an external constraint. As long as ByteDance owns the algorithm, PRC law is always waiting in the wings. Those laws include:
Export-control rules on recommendation algorithms. Data security and cross-border transfer regimes. National security and intelligence laws that impose duties on PRC companies and citizens.
Together, they form a universal answer to every hard question:
Why can’t the algorithm be sold? PRC export controls.
Why can’t certain technical details be disclosed? PRC data laws.
This is not hypothetical. It’s the same concern that animated the original TikTok controversy, just reframed through contracts instead of ownership.
So while TikTok USDS may be auditable, governed by a U.S. board, and compliant with U.S. operational rules, the moment oversight turns upstream—toward the algorithm, updates, or technical dependencies—PRC law reenters the picture.
The result is a U.S. company that is transparent at the edges and opaque at the core. My hunch is that this sovereign control risk is clearly spelled out in any license document and will get disclosed in an IPO.
Putting It Together: Divestment of Optics, Not Control
Taken together, the three pillars tell a consistent story:
ByteDance keeps the algorithm.
ByteDance gets paid and retains an exit.
PRC law remains available to constrain transfer, disclosure, or cooperation.
U.S. regulators oversee the wrapper, not the engine.
That does not mean ByteDance is in exactly the same legal position as before. Governance and ownership optics have changed. Some forms of U.S. oversight are real. But in terms of practical control leverage, ByteDance—and by extension Beijing—may be uncomfortably close to where they started.
The foreign control problem that launched the TikTok saga was never just about equity. It was about who controls the system that shapes attention, culture, and information flow. If that system remains owned upstream, the rest is scaffolding.
The Ouroboros Moment
This is why Congress is likely to be furious once the implications sink in.
The story began with concerns about PRC control. It moved through years of negotiation and political theater. It ends with an “approved structure” that may leave PRC leverage intact—just expressed through licenses, contracts, and sovereign law rather than a majority stake.
The divestment eats its own tail.
Or put more bluntly: the sale may have changed the paperwork, but it did not necessarily change who can say no when it matters most. And that’s control.
As we watch the People’s Liberation Army practicing its invasion of Taiwan, it’s not rocket science to ask how all this will look if the PRC invades Taiwan tomorrow and America comes to Taiwan’s defense. In a U.S.–PRC shooting war, TikTok USDS would likely face either a rapid U.S. distribution ban on national-security grounds (already blessed by SCOTUS), a forced clean-room severance from ByteDance’s algorithm and services, or an operational breakdown if PRC law or wartime measures disrupt the licensed technology the platform depends on.
The TikTok “sale” looks less like a divestiture of control than a divestiture of optics. ByteDance may have reduced its equity stake and ceded governance formalities, but if it retained ownership of the recommendation algorithm and the U.S. company remains dependent on ByteDance by license, then ByteDance’s—and by extension the CCP’s—legal leverage over ByteDance—can remain in a largely similar control position in practice.
TikTok USDS may change the cap table, but it doesn’t necessarily change the sovereign. As long as ByteDance owns the algorithm and PRC law can be invoked to restrict transfer, disclosure, or cooperation without CCP approval, the end state risks looking eerily familiar: a U.S.-branded wrapper around a system Beijing can still influence at the critical junctions. The whole saga starts with bitter complaints in Congress about “foreign control,” ends with “approved structure,” but largely lands right back where it began—an ouroboros of governance optics swallowing itself.
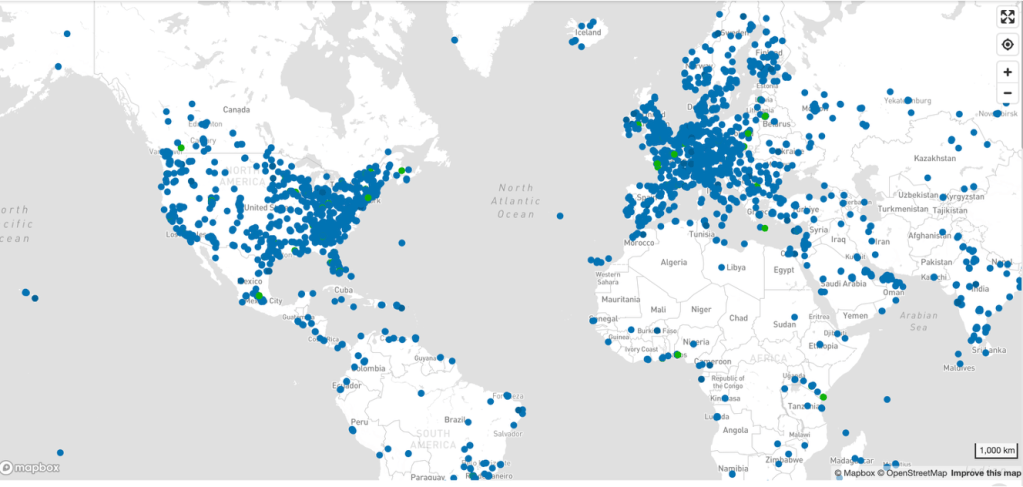
Over the last two weeks, grassroots opposition to data centers has moved from sporadic local skirmishes to a recognizable national pattern. While earlier fights centered on land use, noise, and tax incentives, the current phase is more focused and more dangerous for developers: water.
Across multiple states, residents are demanding to see the “water math” behind proposed data centers—how much water will be consumed (not just withdrawn), where it will come from, whether utilities can actually supply it during drought conditions, and what enforceable reporting and mitigation requirements will apply. In arid regions, water scarcity is an obvious constraint. But what’s new is that even in traditionally water-secure states, opponents are now framing data centers as industrial-scale consumptive users whose needs collide directly with residential growth, agriculture, and climate volatility.
The result: moratoria, rezoning denials, delayed hearings, task forces, and early-stage organizing efforts aimed at blocking projects before entitlements are locked in.
Below is a snapshot of how that opposition has played out state by state over the last two weeks.
State-by-State Breakdown
Virginia
Virginia remains ground zero for organized pushback.
Botetourt County: Residents confronted the Western Virginia Water Authority over a proposed Google data center, pressing officials about long-term water supply impacts and groundwater sustainability.
Hanover County (Richmond region): The Planning Commission voted against recommending rezoning for a large multi-building data center project.
State Legislature: Lawmakers are advancing reform proposals that would require water-use modeling and disclosure.
Georgia
Metro Atlanta / Middle Georgia: Local governments’ recruitment of hyperscale facilities is colliding with resident concerns.
DeKalb County: An extended moratorium reflects a pause-and-rewrite-the-rules strategy.
Monroe County / Forsyth area: Data centers have become a local political issue.
Arizona
The state has moved to curb groundwater use in rural basins via new regulatory designations requiring tracking and reporting.
Local organizing frames AI data centers as unsuitable for arid regions.
Maryland
Prince George’s County (Landover Mall site): Organized opposition centered on environmental justice and utility burdens.
Authorities have responded with a pause/moratorium and a task force.
Indiana
Indianapolis (Martindale-Brightwood): Packed rezoning hearings forced extended timelines.
Greensburg: Overflow crowds framed the fight around water-user rankings.
Oklahoma
Luther (OKC metro): Organized opposition before formal filings.
Michigan
Broad local opposition with water and utility impacts cited.
State-level skirmishes over incentives intersect with water-capacity debates.
North Carolina
Apex (Wake County area): Residents object to strain on electricity and water.
Wisconsin & Pennsylvania
Corporate messaging shifts in response to opposition; Microsoft acknowledged infrastructure and water burdens.
The Through-Line: “Show Us the Water Math”
Lawrence of Arabia: The Well Scene
Across these states, the grassroots playbook has converged:
Pack the hearing.
Demand water-use modeling and disclosure.
Attack rezoning and tax incentives.
Force moratoria until enforceable rules exist.
Residents are demanding hard numbers: consumptive losses, aquifer drawdown rates, utility-system capacity, drought contingencies, and legally binding mitigation.
Why This Matters for AI Policy
This revolt exposes the physical contradiction at the heart of the AI infrastructure build-out: compute is abstract in policy rhetoric but experienced locally as land, water, power, and noise.
Communities are rejecting a development model that externalizes its physical costs onto local water systems and ratepayers.
Water is now the primary political weapon communities are using to block, delay, and reshape AI infrastructure projects.
A grass‑roots “data center and electric grid rebellion” is emerging across the United States as communities push back against the local consequences of AI‑driven infrastructure expansion. Residents are increasingly challenging large‑scale data centers and the transmission lines needed to power them, citing concerns about enormous electricity demand, water consumption, noise pollution, land use, declining property values, and opaque approval processes. What were once routine zoning or utility hearings are now crowded, contentious events, with citizens organizing quickly and sharing strategies across counties and states.
This opposition is no longer ad hoc. In Northern Virginia—often described as the global epicenter of data centers—organized campaigns such as the Coalition to Protect Prince William County have mobilized voters, fundraised for local elections, demanded zoning changes, and challenged approvals in court. In Maryland’s Prince George’s County, resistance has taken on a strong environmental‑justice framing, with groups like the South County Environmental Justice Coalition arguing that data centers concentrate environmental and energy burdens in historically marginalized communities and calling for moratoria and stronger safeguards.
Nationally, consumer and civic groups are increasingly coordinated, using shared data, mapping tools, and media pressure to argue that unchecked data‑center growth threatens grid reliability and shifts costs onto ratepayers. Together, these campaigns signal a broader political reckoning over who bears the costs of the AI economy.
Global Data Centers
Here’s a snapshot of grass roots opposition in Texas, Louisiana and Nevada:
Texas
Texas has some of the most active and durable local opposition, driven by land use, water, and transmission corridors.
Hill Country & Central Texas (Burnet, Llano, Gillespie, Blanco Counties) Grass-roots groups formed initially around high-voltage transmission lines (765 kV) tied to load growth, now explicitly linking those lines to data center demand. Campaigns emphasize:
rural land fragmentation
wildfire risk
eminent domain abuse
lack of local benefit These groups are often informal coalitions of landowners rather than NGOs, but they coordinate testimony, public-records requests, and local elections.
DFW & North Texas Neighborhood associations opposing rezoning for hyperscale facilities focus on noise (backup generators), property values, and school-district tax distortions created by data-center abatements.
ERCOT framing Texas groups uniquely argue that data centers are socializing grid instability risk onto residential ratepayers while privatizing upside—an argument that resonates with conservative voters.
Louisiana
Opposition is newer but coalescing rapidly, often tied to petrochemical and LNG resistance networks.
North Louisiana & Mississippi River Corridor Community groups opposing new data centers frame them as:
“energy parasites” tied to gas plants
extensions of an already overburdened industrial corridor
threats to water tables and wetlands Organizers often overlap with environmental-justice and faith-based coalitions that previously fought refineries and export terminals.
Key tactic: reframing data centers as industrial facilities, not “tech,” triggering stricter land-use scrutiny.
Nevada
Nevada opposition centers on water scarcity and public-land use.
Clark County & Northern Nevada Residents and conservation groups question:
water allocations for evaporative cooling
siting near public or BLM-managed land
grid upgrades subsidized by ratepayers for private AI firms
Distinct Nevada argument: data centers compete directly with housing and tribal water needs, not just environmental values.
“Operation Gatekeeper has exposed a sophisticated smuggling network that threatens our Nation’s security by funneling cutting-edge AI technology to those who would use it against American interests,” said Ganjei. “These chips are the building blocks of AI superiority and are integral to modern military applications. The country that controls these chips will control AI technology; the country that controls AI technology will control the future. The Southern District of Texas will aggressively prosecute anyone who attempts to compromise America’s technological edge.”
That divergence from the prosecutors is not industrial policy. That is incoherence. But mostly it’s just bad advice, likely coming from White House AI Czar David Sacks, Mr. Trump’s South African AI policy advisor who may have a hard time getting a security clearance in the first place..
On one hand, DOJ is rightly bringing cases over the illegal diversion of restricted AI chips—recognizing that these processors are strategic technologies with direct national-security implications. On the other hand, the White House is signaling that access to those same chips is negotiable, subject to licensing workarounds, regulatory carve-outs, or political discretion.
You cannot treat a technology as contraband in federal court and as a commercial export in the West Wing.
Pick one.
AI Chips Are Not Consumer Electronics
The United States does not sell China F-35 fighter jets. We do not sell Patriot missile systems. We do not sell advanced avionics platforms and then act surprised when they show up embedded in military infrastructure. High-end AI accelerators are in the same category.
NVIDIA’s most advanced chips are not merely commercial products. They are general-purpose intelligence infrastructure or what China calls military-civil fusion. They train surveillance systems, military logistics platforms, cyber-offensive tools, and models capable of operating autonomous weapons and battlefield decision-making pipelines with no human in the loop.
If DOJ treats the smuggling of these chips into China as a serious federal crime—and it should—there is no coherent justification for authorizing their sale through executive discretion. Except, of course, money, or in Mr. Sacks case, more money.
Fully Autonomous Weapons—and Selling the Rope
China does not need U.S. chips to build consumer AI. It wants them for military acceleration.Advanced NVIDIA AI chips are not just about chatbots or recommendation engines. They are the backbone of fully autonomous weapons systems—autonomous targeting, swarm coordination, battlefield logistics, and decision-support models that compress the kill chain beyond meaningful human control.
There is an old warning attributed to Vladimir Lenin—that capitalists would sell the rope by which they would later be hanged. Apocryphal or not, it captures this moment with uncomfortable precision.
If NVIDIA chips are powerful enough to underpin autonomous weapons systems for allied militaries, they are powerful enough to underpin autonomous weapons systems for adversaries like China. Trump’s own National Security Strategy statement clearly says previous U.S. elites made “mistaken” assumptions about China such as the famous one that letting China into the WTO would integrate Beijing into the famous rules-based international order. Trump tells us that instead China “got rich and powerful” and used this against us, and goes on to describe the CCP’s well known predatory subsidies, unfair trade, IP theft, industrial espionage, supply-chain leverage, and fentanyl precursor exports as threats the U.S. must “end.” By selling them the most advanced AI chips?
Western governments and investors simultaneously back domestic autonomous-weapons firms—such as Europe-based Helsing, supported by Spotify CEO Daniel Ek—explicitly building AI-enabled munitions for allied defense. That makes exporting equivalent enabling infrastructure to a strategic competitor indefensible.
The AI Moratorium Makes This Worse, Not Better
This contradiction unfolds alongside a proposed federal AI moratorium executive order originating with Mr. Sacks and Adam Thierer of Google’s R Street Institute that would preempt state-level AI protections. States are told AI is too consequential for local regulation, yet the federal government is prepared to license exports of AI’s core infrastructure abroad.
If AI is too dangerous for states to regulate, it is too dangerous to export. Preemption at home combined with permissiveness abroad is not leadership. It is capture.
This Is What Policy Capture Looks Like
The common thread is not national security. It is Silicon Valley access. David Sacks and others in the AI–VC orbit argue that AI regulation threatens U.S. competitiveness while remaining silent on where the chips go and how they are used.
When DOJ prosecutes smugglers while the White House authorizes exports, the public is entitled to ask whose interests are actually being served. Advisory roles that blur public power and private investment cannot coexist with credible national-security policymaking particularly when the advisor may not even be able to get a US national security clearance unless the President blesses it.
A Line Has to Be Drawn
If a technology is so sensitive that its unauthorized transfer justifies prosecution, its authorized transfer should be prohibited absent extraordinary national interest. AI accelerators meet that test.
Until the administration can articulate a coherent justification for exporting these capabilities to China, the answer should be no. Not licensed. Not delayed. Not cosmetically restricted.
And if that position conflicts with Silicon Valley advisers who view this as a growth opportunity, they should return to where they belong. The fact that the US is getting 25% of the deal (which i bet never finds its way into America’s general account), means nothing except confirming Lenin’s joke about selling the rope to hang ourselves, you know, kind of like TikTok.
David Sacks should go back to Silicon Valley.
This is not venture capital. This is our national security and he’s selling it like rope.
Spotify’s insistence that it’s “misleading” to compare services based on a derived per-stream rate reveals exactly how out of touch the company has become with the very artists whose labor fuels its stock price. Artists experience streaming one play at a time, not as an abstract revenue pool or a complex pro-rata formula. Each stream represents a listener’s decision, a moment of engagement, and a microtransaction of trust. Dismissing the per-stream metric as irrelevant is a rhetorical dodge that shields Spotify from accountability for its own value proposition. (The same applies to all streamers, but Spotify is the only one that denies the reality of the per-stream rate.)
Spotify further claims that users don’t pay per stream but for access as if that negates the artist’s per stream rate payments. It is fallacious to claim that because Spotify users pay a subscription fee for “access,” there is no connection between that payment and any one artist they stream. This argument treats music like a public utility rather than a marketplace of individual works. In reality, users subscribe because of the artists and songs they want to hear; the value of “access” is wholly derived from those choices and the fans that artists drive to the platform. Each stream represents a conscious act of consumption and engagement that justifies compensation.
Economically, the subscription fee is not paid into a vacuum — it forms a revenue pool that Spotify divides among rights holders according to streams. Thus, the distribution of user payments is directly tied to which artists are streamed, even if the payment mechanism is indirect. To say otherwise erases the causal relationship between fan behavior and artist earnings.
The “access” framing serves only to obscure accountability. It allows Spotify to argue that artists are incidental to its product when, in truth, they are the product. Without individual songs, there is nothing to access. The subscription model may bundle listening into a single fee, but it does not sever the fundamental link between listener choice and the artist’s right to be paid fairly for that choice.
Less Than Zero Effect: AI, Infinite Supply and Erasing Artist
In fact, this “access” argument may undermine Spotify’s point entirely. If subscribers pay for access, not individual plays, then there’s an even greater obligation to ensure that subscription revenue is distributed fairly across the artists who generate the listening engagement that keeps fans paying each month. The opacity of this system—where listeners have no idea how their money is allocated—protects Spotify, not artists. If fans understood how little of their monthly fee reached the musicians they actually listen to, they might demand a user-centric payout model or direct licensing alternatives. Or they might be more inclined to use a site like Bandcamp. And Spotify really doesn’t want that.
And to anticipate Spotify’s typical deflection—that low payments are the label’s fault—that’s not correct either. Spotify sets the revenue pool, defines the accounting model, and negotiates the rates. Labels may divide the scraps, but it’s Spotify that decides how small the pie is in the first place either through its distribution deals or exercising pricing power.
Three Proofs of Intention
Daniel Ek, the Spotify CEO and arms dealer, made a Dickensian statement that tells you everything you need to know about how Spotify perceives their role as the Streaming Scrooge—“Today, with the cost of creating content being close to zero, people can share an incredible amount of content”.
That statement perfectly illustrates how detached he has become from the lived reality of the people who actually make the music that powers his platform’s market capitalization (which allows him to invest in autonomous weapons). First, music is not generic “content.” It is art, labor, and identity. Reducing it to “content” flattens the creative act into background noise for an algorithmic feed. That’s not rhetoric; it’s a statement of his values. Of course in his defense, “near zero cost” to a billionaire like Ek is not the same as “near zero cost” to any artist. This disharmonious statement shows that Daniel Ek mistakes the harmony of the people for the noise of the marketplace—arming algorithms instead of artists.
Second, the notion that the cost of creating recordings is “close to zero” is absurd. Real artists pay for instruments, studios, producers, engineers, session musicians, mixing, mastering, artwork, promotion, and often the cost of simply surviving long enough to make the next record or write the next song. Even the so-called “bedroom producer” incurs real expenses—gear, software, electricity, distribution, and years of unpaid labor learning the craft. None of that is zero. As I said in the UK Parliament’s Inquiry into the Economics of Streaming, when the day comes that a soloist aspires to having their music included on a Spotify “sleep” playlist, there’s something really wrong here.
Ek’s comment reveals the Silicon Valley mindset that art is a frictionless input for data platforms, not an enterprise of human skill, sacrifice, and emotion. When the CEO of the world’s dominant streaming company trivializes the cost of creation, he’s not describing an economy—he’s erasing one.
While Spotify tries to distract from the “per-stream rate,” it conveniently ignores the reality that whatever it pays “the music industry” or “rights holders” for all the artists signed to one label still must be broken down into actual payments to the individual artists and songwriters who created the work. Labels divide their share among recording artists; publishers do the same for composers and lyricists. If Spotify refuses to engage on per-stream value, what it’s really saying is that it doesn’t want to address the people behind the music—the very creators whose livelihoods depend on those streams. In pretending the per-stream question doesn’t matter, Spotify admits the artist doesn’t matter either.
Less Than Zero or Zeroing Out: Where Do We Go from Here?
The collapse of artist revenue and the rise of AI aren’t coincidences; they’re two gears in the same machine. Streaming’s economics rewards infinite supply at near-zero unit cost which is really the nugget of truth in Daniel Ek’s statements. This is evidenced by Spotify’s dalliances with Epidemic Sound and the like. But—human-created music is finite and costly; AI music is effectively infinite and cheap. For a platform whose margins improve as payout obligations shrink, the logical endgame is obvious: keep the streams, remove the artists.
Two-sided market math. Platforms sell audience attention to advertisers and access to subscribers. Their largest variable cost is royalties. Every substitution of human tracks with synthetic “sound-alikes,” noise, functional audio, or AI mashup reduces royalty liability while keeping listening hours—and revenue—intact. You count the AI streams just long enough to reduce the royalty pool, then you remove them from the system, only to be replace by more AI tracks. Spotify’s security is just good enough to miss the AI tracks for at least one royalty accounting period.
Perpetual content glut as cover. Executives say creation costs are “near zero,” justifying lower per-stream value. That narrative licenses a race to the bottom, then invites AI to flood the catalog so the floor can fall further.
Training to replace, not to pay. Models ingest human catalogs to learn style and voice, then output “good enough” music that competes with the very works that trained them—without the messy line item called “artist compensation.”
Playlist gatekeeping. When discovery is centralized in editorial and algorithmic playlists, platforms can steer demand toward low-or-no-royalty inventory (functional audio, public-domain, in-house/commissioned AI), starving human repertoire while claiming neutrality.
Investor alignment. The story that scales is not “fair pay”; it’s “gross margin expansion.” AI is the lever that turns culture into a fixed cost and artists into externalities.
Where does that leave us? Both streaming and AI “work” best for Big Tech, financially, when the artist is cheap enough to ignore or easy enough to replace. AI doesn’t disrupt that model; it completes it. It also gives cover through a tortured misreading through the “national security” lens so natural for a Lord of War investor like Mr. Ek who will no doubt give fellow Swede and one of the great Lords of War, Alfred Nobel, a run for his money. (Perhaps Mr. Ek will reimagine the Peace Prize.) If we don’t hard-wire licensing, provenance, and payout floors, the platform’s optimal future is music without musicians.
Plato conceived justice as each part performing its proper function in harmony with the whole—a balance of reason, spirit, and appetite within the individual and of classes within the city. Applied to AI synthetic works like those generated by Sora 2, injustice arises when this order collapses: when technology imitates creation without acknowledging the creators whose intellect and labor made it possible. Such systems allow the “appetitive” side—profit and scale—to dominate reason and virtue. In Plato’s terms, an AI trained on human art yet denying its debt to artists enacts the very disorder that defines injustice.
When Ed Newton-Rex left Stability AI, he didn’t just make a career move — he issued a warning. His message was simple: we’ve built an industry that moves too fast to be honest.
AI’s defenders insist that regulation can’t keep up, that oversight will “stifle innovation.” But that speed isn’t a by-product; it’s the business model. The system is engineered for planned obsolescence of accountability — every time the public begins to understand one layer of technology, another version ships, invalidating the debate. The goal isn’t progress; it’s perpetual synthetic novelty, where nothing stays still long enough to be measured or governed, and “nothing says freedom like getting away with it.”
We’ve seen this play before. Car makers built expensive sensors we don’t want that fail on schedule; software platforms built policies that expire the moment they bite. In both cases, complexity became a shield and a racket — “too dynamic to question.” And yet, like those unasked-for, but paid for, features in the cars we don’t want, AI’s design choices are too dangerous to ignore. (Like what if your brakes really are going out, not just the sensor is malfunctioning.)
Ed Newton-Rex’s point — echoed in his tweets and testimony — is that the industry has mistaken velocity for virtue. He’s right. The danger is not that these systems evolve too quickly to regulate; it’s that they’re designed that way designed to fail just like that brake sensor. And until lawmakers recognize that speed itself is a form of governance, we’ll keep mistaking momentum for inevitability.
Xi Jinping’s new article in Qiushi (the Chinese Communist Party Central Committee’s flagship theoretical public policy journal) repackages a familiar message: China will promote the “healthy and high-quality development” of the private economy, but under the leadership of the Chinese Communist Party. This is expressed in China’s statutory law as the “Private Economy Promotion Law.” And of course we have to always remember that under the PRC “constitution,” statutes are primarily designed to safeguard the authority and interests of the Chinese Communist Party (CCP) rather than to protect the rights and privileges of individuals—because individuals don’t really have any protections against the CCP.
For U.S. policymakers weighing what to do about TikTok, this is not reassuring rhetoric in my view. It is instead a reminder that, in China, private platforms ultimately operate within a legal-and-political framework that gives state-security organs binding powers over companies, the Chinese people, and their data.
In another show of support for China’s private sector, Beijing has released the details of a speech from President Xi Jinping which included vows the country would guarantee a level playing field for private firms, safeguard entrepreneurs’ lawful rights and interests, and step up efforts to solve their long-standing challenges, including overdue payments.
The full address, delivered in February to a group of China’s leading entrepreneurs, had not been made available to the public before Friday, when Qiushi – the ruling Communist Party’s theoretical journal – posted a transcript on its website.
“The policies and measures to promote the development of the private economy must be implemented in a solid and thorough manner,” Xi said in February. “Whatever the party Central Committee has decided must be resolutely carried out – without ambiguity, delay, or compromise
I will try to explain why the emphasis of Xi’s policy speech matters, and why the divest-or-ban logic for TikTok under US law (and it is a law) remains intact regardless of what may seem like “friendly” language about private enterprise. It’s also worth remembering that whatever the result of the TikTok divestment may be, it’s just another stop along the way in the Sino-American struggle—or something more kinetic. As Clausewitz wrote in his other famous quotation, the outcomes produced by war are never final. (See Book I Chapter 1 aka the good stuff.) Even the most decisive battlefield victory may have no lasting political achievement. As we have seen time and again, the termination of one conflict often produces the necessary conditions for future conflict.
What Xi’s piece actually signals
Xi’s article combines pro-private-sector language (property-rights protection, market access, financing support) with an explicit call for Party leadership and ideological guidance in the private economy. In other words, the promise is growth within control, and not just any control but the control of the Party. There is no carve‑out from national-security statutes, no “TikTok exemption,” and no suggestion that private firms can decline cooperation when state-security laws apply consistent with China’s “unrestricted warfare” doctrine.
Recall that the CCP has designated the TikTok algorithm as a strategic national asset, and “national” in this context and the context of Xi’s article means the Chinese Communist Party of which Xi is President-for-Life. This brother is not playing.
The laws that define the TikTok Divestment risk (not the press releases)
The core concern about TikTok is jurisdiction, or the CCP’s extra-territorial jurisdiction, a concept we don’t fully comprehend. Xi’s Qiushi article promises support for private firms under Party leadership. That means that the National Intelligence Law, Cybersecurity Law, Counter‑Espionage Law, and China’s data‑export regime remain in force and are controlling authority over companies like TikTok. For U.S. reviewers like CIFIUS, that means ByteDance‑controlled TikTok is, by design, subject to compelled, confidential cooperation with state‑security organs.
As long as the TikTok platform and algorithm is ultimately controlled by a company subject to the CCP’s security laws, U.S. reviewers correctly assume those laws can reach the service, even if operations are partly localized abroad. MTP readers will recall the four pillars of China’s statutory security regime that matter most in this context, being:
National Intelligence Law (2017). Requires all organizations and citizens to support, assist, and cooperate with state intelligence work, and to keep that cooperation secret. Corporate policies and NDAs do not trump statutory duties, especially in the PRC.
Cybersecurity Law (2017). Obligates “network operators” to provide technical support and assistance to public‑security and state‑security organs, and sets the baseline for security reviews and Multi‑Level Protection (MLPS) obligations.
Counter‑Espionage Law (2023 amendment). Broadens the scope of what counts as “espionage” to include data, documents, and materials related to national security or the “national interest,” increasing the zone where requests can be justified.
Data regime (Data Security Law (DSL), Personal Information Protection Law (PIPL), and the Cyberspace Administration of China (CAC) regulatory measures). Controls cross‑border transfers through security assessments or standard contracts and allows denials on national‑security grounds. Practically, many datasets can’t leave China without approval—and keys/cryptography used onshore must follow onshore rules.
None of the above is changed by the Private Economy Promotion Law or by Xi’s supportive tone toward entrepreneurs. The laws remain superior in any conflict such as the TikTok divest-or-ban law.
It is these laws that are at the bottom of U.S. concerns about TikTok’s data scraping–it is, after all, spyware with a soundtrack. There’s a strong case to be made that U.S. artists, songwriters, creators and fans are all dupes of TikTok as a data collection tool in a country that requires its companies to hand over to the Ministry of State Security all it needs to support the intelligence mission (MSS is like the FBI and CIA in one agency with a heavy ration of FSB).
Zhang Yiming, founder of ByteDance and former public face of TikTok, stepped down as CEO in 2021 but remains Chairman and key shareholder. He controls more than half of the company’s voting rights and retains about a 21% stake. That also makes him China’s richest man. Though low-profile publicly, he is actively guiding ByteDance’s AI strategy and long-term direction. Mr. Zhang does not discuss this part. It should come as no surprise–according to his Wikipedia page, Mr. Zhang understands what happens when you don’t toe the Party line:
ByteDance’s AI strategy is built on aggressive large-scale data scraping including from TikTok. Its proprietary crawler, ByteSpider, dominates global web-scraping traffic, collecting vast amounts of content at speeds far beyond rivals like OpenAI. This raw data fuels TikTok’s recommendation engine and broader generative AI development, giving ByteDance rapid adaptability and massive training inputs. Unlike OpenAI, which emphasizes curated datasets, ByteDance prioritizes scale, velocity, and real-time responsiveness, integrating insights from TikTok user behavior and the wider internet. This approach positions ByteDance as a formidable AI competitor, leveraging its enormous data advantage to strengthen consumer products, expand generative AI capabilities, and consolidate global influence.
I would find it very, very hard to believe that Mr. Zhang is not a member of the Chinese Communist Party, but in any event he understands very clearly what his role is under the National Intelligence Law and related statutes. Do you think that standing up to the MSS to protect the data privacy of American teenagers is consistent with “Xi Jinping Thought”?
Why this makes TikTok’s case harder, not easier
For Washington, the TikTok problem is not market access or entrepreneurship. It’s the data governance chain. Xi’s article underscores that private firms are expected to align with the Party Center’s decisions and to embed Party structures. Combine that political expectation with the statutory duties described above, and you get a simple inference: if China’s security services want something—from data access to algorithmic levers—ByteDance and its affiliates are obliged to give it to them or at least help, and are often barred from disclosing that help.
That’s why divestiture has become the U.S. default: the only durable mitigation against TikTok is to place ownership and effective control outside PRC legal reach, with clean technical and organizational separation (code, data, keys, staffing, and change control). Anything short of that leaves the fundamental risk untouched.
Where the U.S. law and process fit
Congress’s divest‑or‑ban statute requires TikTok to be controlled by an entity not subject to PRC direction, on terms approved by U.S. authorities. Beijing’s export‑control rules on recommendation algorithms make a full transfer difficult if not impossible; that’s why proposals have floated a U.S. “fork” with separate code, ops, and data. But Xi’s article doesn’t move the ball: it simply reinforces that CCP jurisdiction over private platforms is a feature, not a bug, of the system.
Practical implications (policy and product)
For policymakers: Treat Xi’s article as confirmation that political control and security statutes are baked in. Negotiated “promises” won’t outweigh legal duties to assist intelligence work. Any compliance plan that assumes voluntary transparency or a “hands‑off” approach is fragile by design.
For platforms: If you operate in China, assume compelled and confidential cooperation is possible and in this case almost a certainty if it hasn’t already happened. Architect China operations as least‑privilege, least‑data environments; segregate code and keys; plan for outbound data barrrers as a normal business condition.
For users and advertisers: The risk discussion is about governance and jurisdiction, not whether a particular management team “would never do that.” They would. Corporate intent can’t override state legal authority particularly when the Party’s Ministry of State Security is doing the asking.
Now What?
Xi’s article does not soften TikTok’s regulatory problem in the United States. If anything, it sharpens it by reiterating that the private economy advances underthe Party’s direction, never apart from it. When you combine Mr. Zhang’s role with Bytedance in China’s AI national champions, it’s pretty obvious whose side TikTok is on.
Wherever the divest-or-ban legislation ends up, it will inevitably set the stage for the next conflict. If I had to bet today, my bet is that Xi has no intention of making a deal with the US that involves giving up the TikTok algorithm in violation of the Party’s export-control rules and access to US user data for AI training.